Análisis Léxico
El Analizador Léxico (Scanner) es el primer paso de la fase de análisis. Su trabajo es leer el archivo de texto (caracteres sueltos) y agruparlos en unidades con significado llamadas tokens o componentes léxicos.
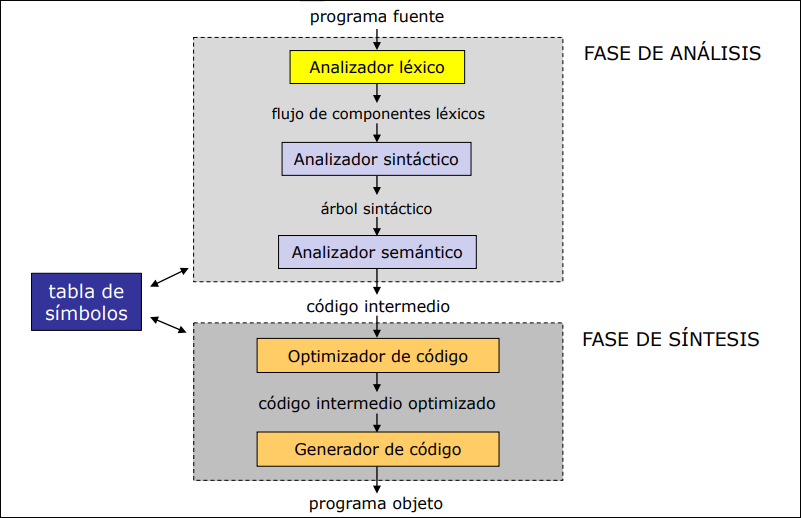
2.1 Estructura
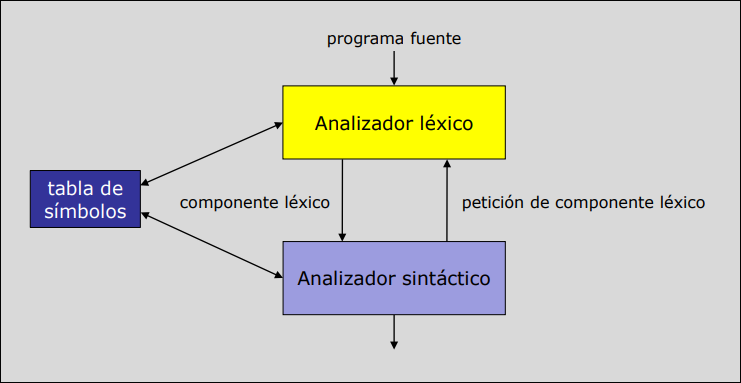
Sección titulada «2.1 Estructura»Los analizadores sintáctico (recibe los tokens y crea una estructura jerárquica que describe la estructura gramatical del código) y léxico funcionan según el patrón productor-consumidor, siguiendo el siguiente esquema:
- Consumidor (Sintáctico): le pide al léxico el siguiente token.
- Productor (Léxico): lee los caracteres necesarios, forma el token y se lo entrega.
2.1.1 Tareas
Sección titulada «2.1.1 Tareas»- Reconoce los componentes léxicos de lenguaje.
- Elimina aquellos caracteres de código fuente sin significado gramatical (espacios en blanco, tabulaciones, comentarios, saltos de línea …)
- Reconoce los identificadores de variables, tipo, constantes, métodos, etc. y los guarda en la tabla de símbolos (identifica tokens).
- Avisa de errores léxicos detectados y los relaciona con un mensaje de error con el lugar en el que aparecen en el programa fuente.
2.1.2 Ventajas
Sección titulada «2.1.2 Ventajas»Este modelo proporciona simplicidad porque el analizador sintáctico no tiene que preocuparse por espacios en blanco o comentarios.
Eficiencia porque el análisis léxico consume mucho tiempo de CPU, al separarlo podemos usar técnicas de lectura rápida.
Portabilidad, si cambias de caracteres (ej. de ASCII a Unicode), solo cambias el analizar léxico.
2.1.3 Diseño
Sección titulada «2.1.3 Diseño»- Especificación de los términos del análisis léxico mediante el uso de expresiones regulares.
- Diseño de un autómata finito que permita reconocer las expresiones regulares propuestas
- Realización de autómata finito deterministas mínimo que permita realizar un reconocimiento eficiente.
- Diseño y realización de un sistema de entrada.
- Diseño y realización de una tabla de símbolos.
- Diseño y realización de una estrategia de manejo de errores.
2.2 Especificación del Analizador
Sección titulada «2.2 Especificación del Analizador»2.2.1 Términos del Análisis Léxico
Sección titulada «2.2.1 Términos del Análisis Léxico»- Componente léxico (token): símbolo terminal de la gramática que define el lenguaje fuente. Pueden ser signos de puntuación, operadores, palabras reservadas, identificadores …
- Patrón: expresión regular que define el conjunto de cadenas correspondientes a un componente léxico.
[0-9]+identifica cada una cadena de una o más cifras, correspondiente al componente léxico NÚMERO_ENTERO. - Lexema: cadena de caracteres presente en el código fuente y que coincide con el patrón de un componente léxico. Por ejemplo,
453coincide con el patrón de NÚMERO_ENTERO. - Atributos: acompañan a cada componente léxico encontrado y permiten su identificación y análisis posterior. En la práctica un único atributo apunta a una entrada de la tabla de símbolos

Si por ejemplo tenemos la sentencia FORTRAN E = C ** 2 se traduce como:
- <IDENTIFICADOR, apuntador en la tabla de símbolos a la entrada de E>
- <OP_ASIGNACIÓN>
- <IDENTIFICADOR, apuntador en la tabla de símbolos a la entrada de C>
- <OP_EXPONENTE>
- <NÚMERO_ENTERO, valor entero 2>
2.2.2 Expresiones Regulares
Sección titulada «2.2.2 Expresiones Regulares»Una expresión regular permite representar patrones de caracteres. El conjunto de cadenas representado por recibe el nombre de lenguaje generado por , y se escribe . Para un alfabeto diremos que:
- es una expresión regular y
- El símbolo (palabra vacía) es una expresión regular y
- Cualquier símbolo es una expresión regular y
A partir de estas expresiones regulares básicas pueden construirse expresiones regulares más complejas aplicando las siguientes operaciones (vistas todas en talf):
- Concatenación
- Unión
- Cierre o clausrua
Ejemplos:
- La expresión regular designa el conjunto .
- La expresión regular designa . Otra expresión regular para el mismo conjunto es . Se dice que ambas expresiones regulares son equivalentes.
- La expresión regular designa .
- La expresión regular designa el conjunto de todas las cadenas de y . Otra expresión regular equivalente es .
- La expresión regular designa el conjunto que contiene la cadena a y todas aquellas con cero o más a seguidas de una b.
2.2.3 Definiciones Regulares
Sección titulada «2.2.3 Definiciones Regulares»Por conveniencia, daremos nombres a las expresiones regulares, utilizando dichos nombres como si fuesen símbolos: Ejemplo: Definimos los números sin signo en Pascal como: digito \rightarrow 0|1|...|9$$$$digitos \rightarrow \text{digito } digito *$$$$fracción \rightarrow .digito| \epsilon
2.2.4 Simplificación de la notación
Sección titulada «2.2.4 Simplificación de la notación»- Cero o un caso: El operador unitario postfijo significa “cero o un caso de”. Así abrevia , y designa el lenguaje .
- Uno o más casos: El operador unitario postfijo significa “uno o más casos de”. Si designa el lenguaje , entonces designa . Se cumple que y .
- Clases de caracteres: La notación designa la expresión regular . designa la expresión .
Ejemplo: Ahora definimos los números sin signo en Pascal como:
2.3 Autómatas Finitos
Sección titulada «2.3 Autómatas Finitos»Lo mismo que vimos en Teoría de Autómatas y Lenguajes formales:
2.3.1 AFN
Sección titulada «2.3.1 AFN»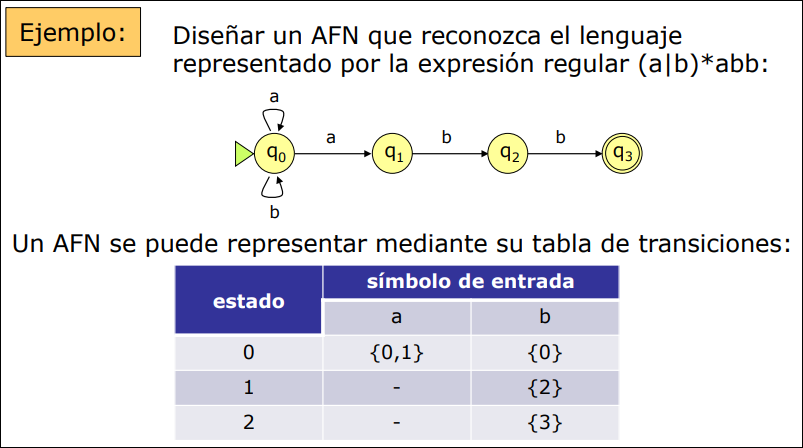
Para construir un AFN de un modo sistemático empleamos la Construcción de Thompson, que utiliza tres reglas básicas:
-
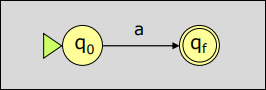
Para el símbolo , se construye el AFN siguiente:
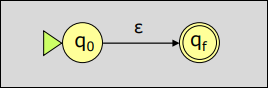
-
Para el símbolo , se construye el AFN siguiente:
-
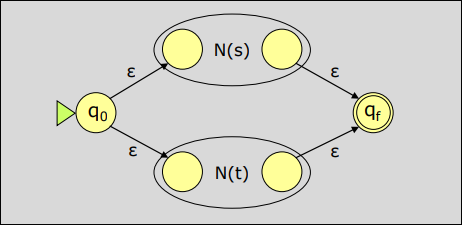
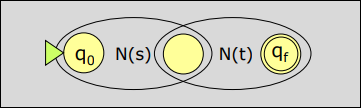
Supongamos que y son AFN para las expresiones regulares y :
- Para la expresión regular se construye el AFN
- Para la expresión regular se construye el AFN .
- Para la expresión regular se construye el AFN siguiente:
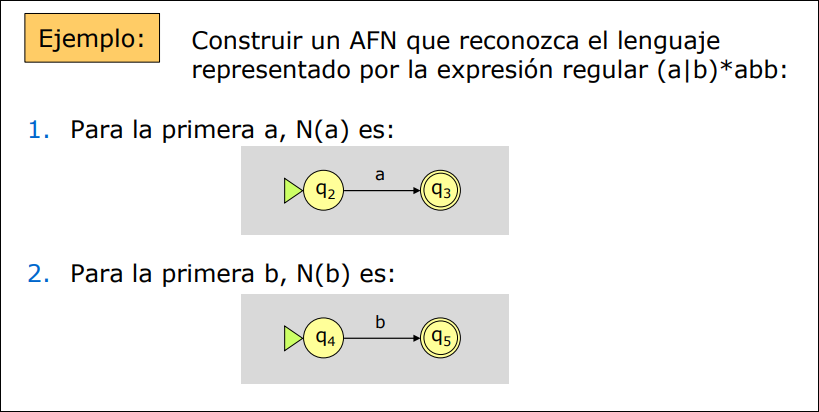
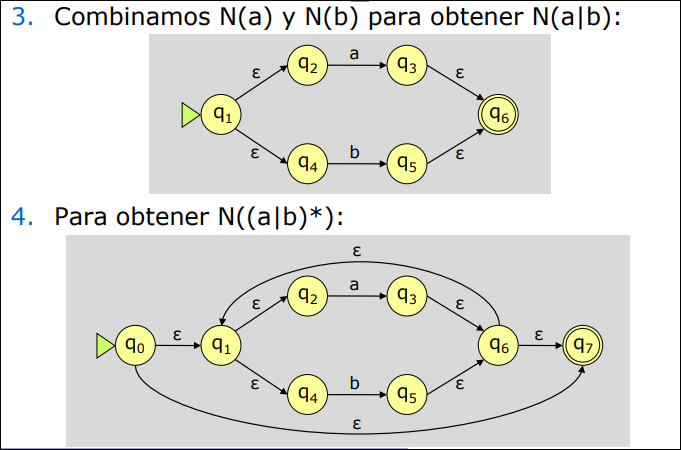
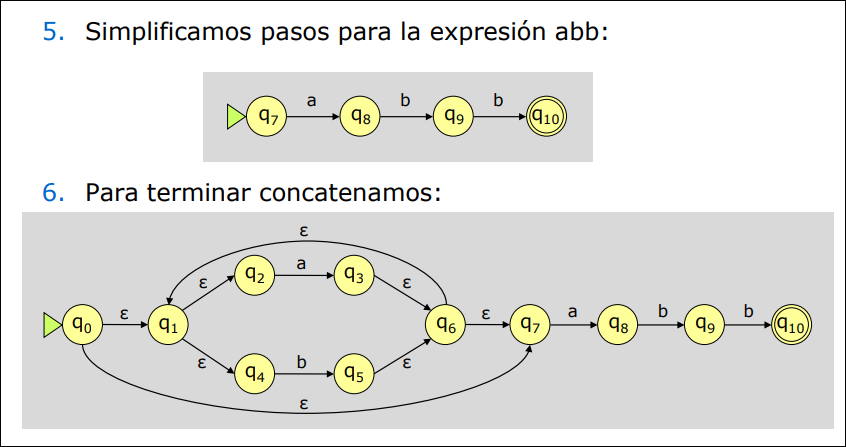
2.3.2 Autómata Finito Determinista
Sección titulada «2.3.2 Autómata Finito Determinista»Necesitamos convertir el AFN a un AFD para ello empleamos el método de construcción de subconjuntos para obtener el AFD equivalente a un AFN dado. Este AFD será más sencillo de programar. Este algoritmo lo vimos en TALF.
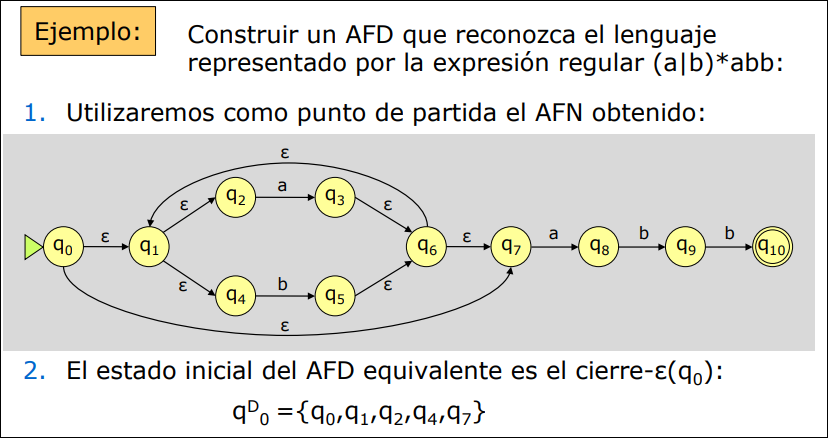

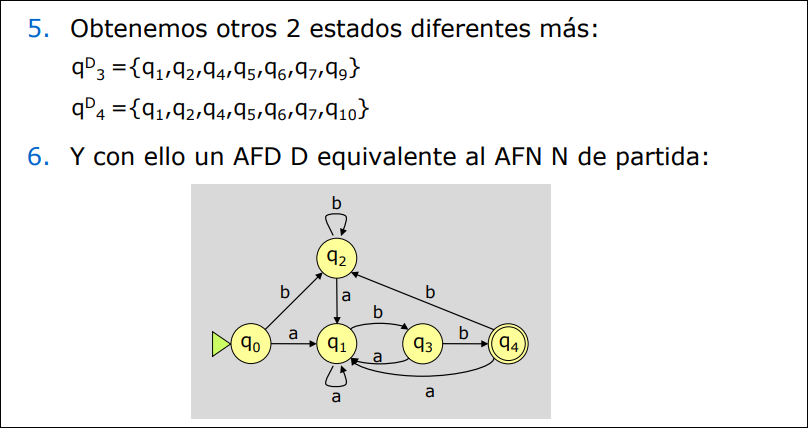

2.3.3 AFD Mínimo Equivalente
Sección titulada «2.3.3 AFD Mínimo Equivalente»Un analizador léxico será más eficiente cuanto menor sea el número de estados del AFD correspondiente. Para cualquier AFD existe un AFD mínimo equivalente.
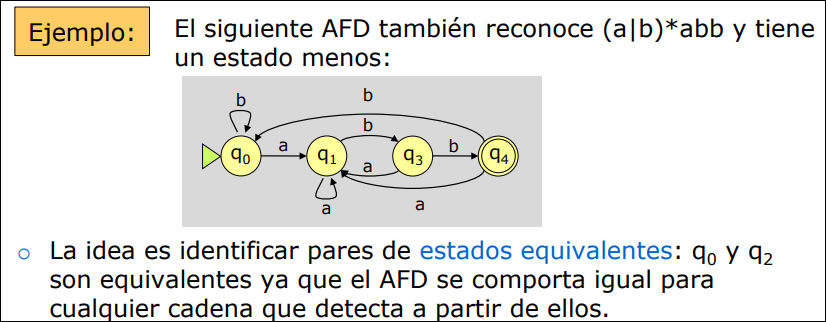

2.3.4 Construcción del Analizador
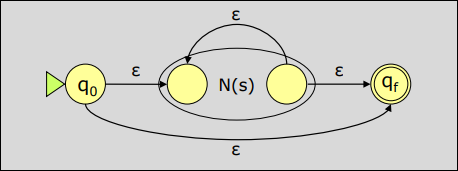
Sección titulada «2.3.4 Construcción del Analizador»El analizador léxico se construirá a partir de la agregación de AFD organizados según un orden conveniente. Siempre se debe reconocer la cadena más larga. El último carácter leído será devuelto al flujo para ser leído en la siguiente iteración.
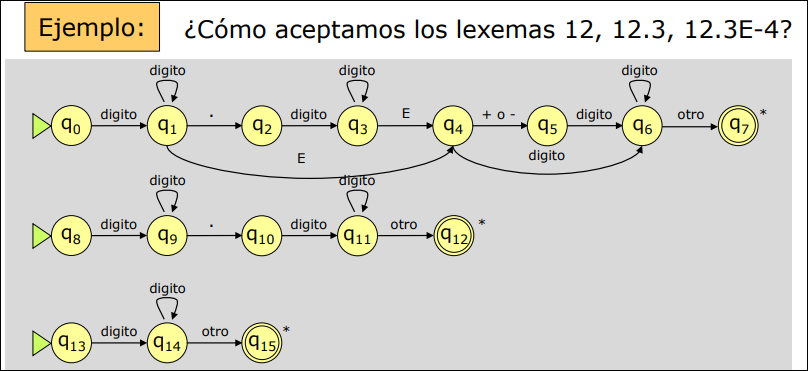
Podemos integrar los tres autómatas anteriores en el siguiente autómata:
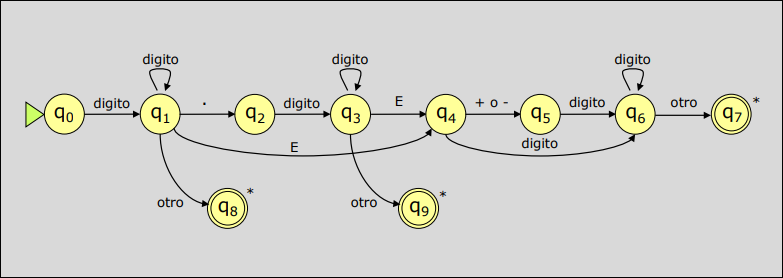
2.4 Sistema de Entrada
Sección titulada «2.4 Sistema de Entrada»El sistema de entrada es un conjunto de rutinas que interactúan con el sistema operativo para la lectura de datos del programa fuente. El sistema de entrada y el analizador léxico funcionan según el patrón productor-consumidor.
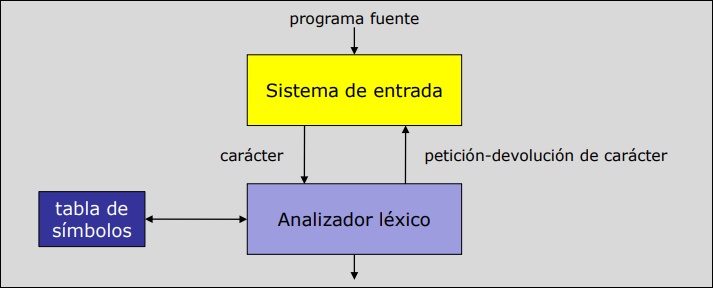
La separación del sistema de entrada supone una mejora en:
- Eficiencia: supongamos un analizador léxico en C que tiene que acceder a un carácter de un fichero. Este carácter pasa del disco a la memoria gestionada por el sistema operativo, a una estructura
FILE, a una variablestringdel analizador. Urge soluciones. - Portabilidad: ya que el sistema de entrada es el único componente del compilador que se comunica con el sistema operativo. Para cambiar de plataforma sólo tenemos que cambiar el sistema de entrada.
2.4.1 La Memoria Intermedia
Sección titulada «2.4.1 La Memoria Intermedia»El analizador léxico debe detectar el componente léxico con el lexema más largo posible. Se necesita poder leer caracteres de un modo anticipado. Para resolver este problema, se debe incorporar una memoria intermedia de modo que:
- Se pueda almacenar un bloque de caracteres en disco y apuntar el fragmento ya analizado.
- En caso de devolución de caracteres al flujo de entrada se pueda mover un apuntador tantas posiciones como caracteres a devolver.
2.4.2 Métodos de Gestión de la Entrada
Sección titulada «2.4.2 Métodos de Gestión de la Entrada»Cualquier sistema de entrada debe satisfacer:
- Ser lo más rápido posible
- Permite un acceso eficiente a disco
- Hacer un uso eficiente de memoria
- Soportar lexemas de longitud considerable
- Tener disponibles el lexema actual y el anterior
Método del Par de Memorias Intermedias
Sección titulada «Método del Par de Memorias Intermedias»El método del par de memorias intermedias divide la memoria intermedia en dos mitades de bytes cada una ( debe ser múltiplo de la longitud de la unidad de asignación).
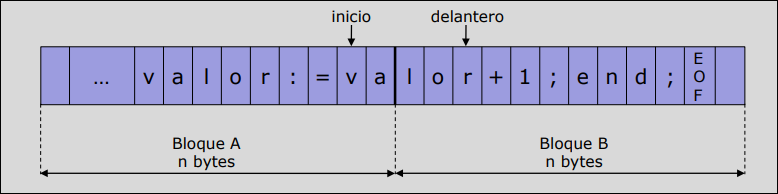
Al principio, los punteros inicio y delantero apuntan al primer caracter de un lexema. A medida que el analizador pide caracteres, delantero se mueve hacia delante. Tras detectar un patrón, inicio avanza hasta la posición de delantero y se inicia el análisis del siguiente lexema. Cada vez que se mueve delantero:
- Se comprueba si se ha alcanzado el final de fichero
- Se comprueba si se ha alcanzado el final de un bloque. En caso de alcanzarse, se solicita un nuevo bloque al SO.
Limitaciones:
-
Tamaño del lexema limitado por : Aunque en condiciones ideales un lexema podría ocupar hasta , el sistema solo garantiza el reconocimiento de lexemas de longitud máxima . Si un lexema supera este tamaño, al avanzar el puntero
delanterohacia un nuevo bloque, se sobrescribirá la memoria donde se encontraba el punteroinicio, perdiendo el comienzo del lexema antes de ser procesado. -
Ineficiencia en el avance: Por cada carácter que avanza el puntero
delantero, el sistema debe realizar tres comprobaciones lógicas: si es fin de fichero, si es fin del bloque A o si es fin del bloque B. Esta carga computacional se optimiza en implementaciones reales mediante el uso de centinelas (caracteres especiales al final de cada bloque).
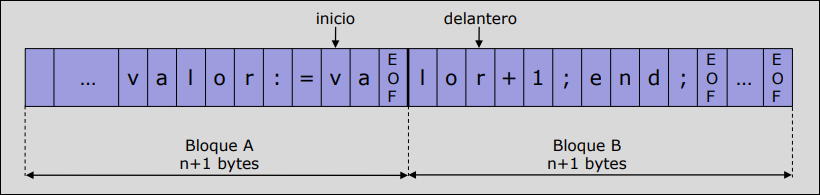
Método del Centinela
Sección titulada «Método del Centinela»En el método del centinela se añade un byte más a cada bloque, en el que se guardará un carácter centinela (EOF). De este modo, se hace una sola comprobación lógica cada vez que avanza delantero. Si la comprobación es positiva, se analiza cuán de los tres casos es.
2.5 Tabla de Símbolos
Sección titulada «2.5 Tabla de Símbolos»La tabla de símbolos es la estructura de datos utilizada por el compilador para gestionar los identificadores que aparecen en el programa fuente: constantes, variables, tipos, funciones,…
Cuando el compilador encuentra un identificador, guarda en esta tabla la información que lo caracteriza: nombre, categoría (subrutina, variable, constante, clase, tipo,…), la dirección de memoria que se le asigna, su tamaño, etc.
Cuando el identificador es referenciado en el programa, el compilador consulta la tabla de símbolos y obtiene la información que necesita. Una vez fuera del ámbito del identificador, se elimina de la tabla de símbolos.
Durante la compilación:
- El analizador léxico, cuando encuentra un identificador, comprueba que está en la tabla de símbolos. Si no lo está, crea una nueva entrada para el mismo.
- El analizador sintáctico añade información a los campos de los atributos. Pero también puede crear nuevas entradas si se definen nuevos tipos de datos como palabras reservadas
- El análisis semántico debe acceder a la tabla para consultar los tipos de datos de los símbolos
- El generador de código puede: 1) leer el tipo de dato de una variable para la reserva de espacio; 2) guardar la dirección de memoria en la que se almacenará una variable.
2.5.1 Palabras Reservadas
Sección titulada «2.5.1 Palabras Reservadas»Algunos lenguajes reservan algunas palabras que no pueden utilizarse como identificadores: printf, for, if, while, etc. Pueden distinguirse:
- Definiéndolas mediante expresiones regulares, y asociándoles un componente léxico particular.
- Mediante una tabla de palabras clave. Cada vez que se encuentra un lexema correspondiente a un identificador se busca en esta tabla.
- Insertándolas al principio de la tabla de símbolos. Se gestionan en la misma tabla palabras clave e identificadores.
La tabla de símbolos se inicializa en las primeras posiciones con las palabras reservadas del lenguaje, ordenadas por orden alfabético. Cuando se encuentra un nombre en el código fuente se consulta la tabla de símbolos:
- Si se encuentra entre las palabras reservadas se devuelve su componente léxico al analizador sintáctico.
- Si se encuentra después de las palabras reservadas es un identificador previamente encontrado.
- Si no se encuentra en la tabla de símbolos, se añade como un nuevo identificador.
De este modo se reduce el tamaño del AFD y se aumenta la eficiencia del análisis léxico.
2.5.2 Estructura de la Tabla de Símbolos.
Sección titulada «2.5.2 Estructura de la Tabla de Símbolos.»La tabla de símbolos se estructura en un conjunto de registros, cuya longitud suele ser fija, conteniendo el lexema encontrado y un conjunto de atributos para su componente léxico. Hay dos formas de almacenamiento:
-
Estructura Interna: Si reservas 32 caracteres para cada nombre y el programador usa variables cortas como
iox, desperdicias mucho espacio. Si el programador usa un nombre de 33 caracteres, lo cortas y causas errores.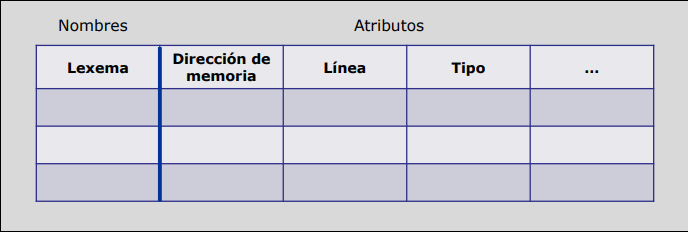
-
Estructura Externa: Esta estructura no exige una longitud fija para los identificadores, por lo que se aprovecha mejor el espacio de almacenamiento.
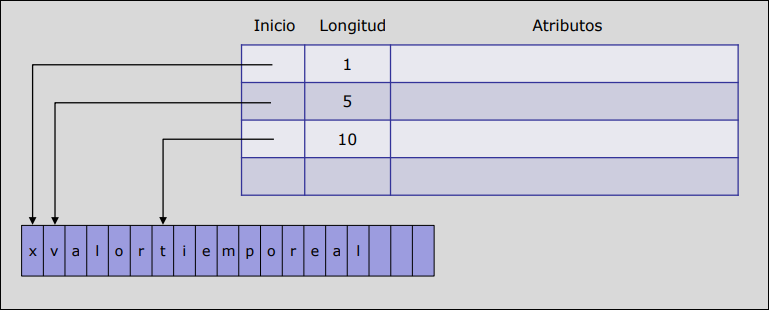
2.5.3 Estructura de la Tabla de Símbolos.
Sección titulada «2.5.3 Estructura de la Tabla de Símbolos.»La tabla de símbolos funciona como una base de datos en la que el campo calve es el lexema del símbolo. Las operaciones que se ejecutan sobre la tabla son:
- Buscar un lexema y el contenido de sus atributos.
- Insertar un nuevo registro previa comprobación de su no existencia.
- Modificar la información contenida en un registro. En general, se realiza una operación de adición de información.
Además, en lenguajes con estructura de bloque:
- Nuevo bloque: comienzo de un nuevo bloque.
- Fin de bloque: final de un bloque.
2.5.4 Organización de la Tabla
Sección titulada «2.5.4 Organización de la Tabla»Las tablas de símbolos se organizan de dos maneras:
- Tablas no ordenadas. Generadas con vectores o listas. Poco eficientes pero fáciles de programar.
- Tablas ordenadas. Permiten definir el tipo diccionario. Utilizan estructuras de tipo vector o lista ordenada, árboles binarios, árboles equilibrados (AVL), tablas de dispersión (hash), etc.
Analizaremos el uso de algunas de estas estructuras para organizar una tabla de símbolos. Nos ocuparemos de su uso en la traducción de lenguajes con estructura de bloques. Las reglas de ámbito, propias de cada lenguaje, determinan la definición de cada lexema en cada momento de la compilación.
Tablas de Símbolos no Ordenadas
Sección titulada «Tablas de Símbolos no Ordenadas»Las tablas de símbolos no ordenadas usan un vector o una lista. Se añade una pila auxiliar de apuntadores de índice de bloque, para marcar el comienzo de los símbolos que corresponden a un bloque. Al terminar un bloque, se eliminan todos los símbolos desde el siguiente al apuntado hasta el final de la tabla de símbolos.

Admite las siguientes operaciones:
- Inserción. Cuando se encuentra la declaración de un nuevo símbolo, se verifica que no se encuentra en el último bloque. Si no está, se inserta en la última posición de la tabla, si está, se devuelve un error.
- Búsqueda. La búsqueda se hace desde el final de la tabla hacia el principio. Si se encuentra, se corresponde a la declaración realizada en el bloque más próximo.
- Nuevo bloque. Cuando empieza un bloque se añade en la pila un apuntador al último símbolo de la tabla.
- Fin de bloque. Cuando termina un bloque, se eliminan todos los símbolos del mismo desde el siguiente al de inicio, apuntado desde la pila. Luego se elimina el índice de la pila.
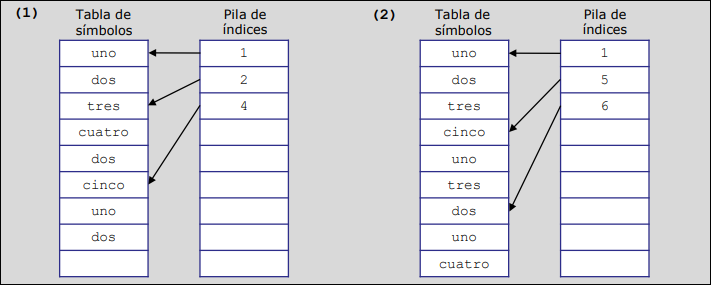
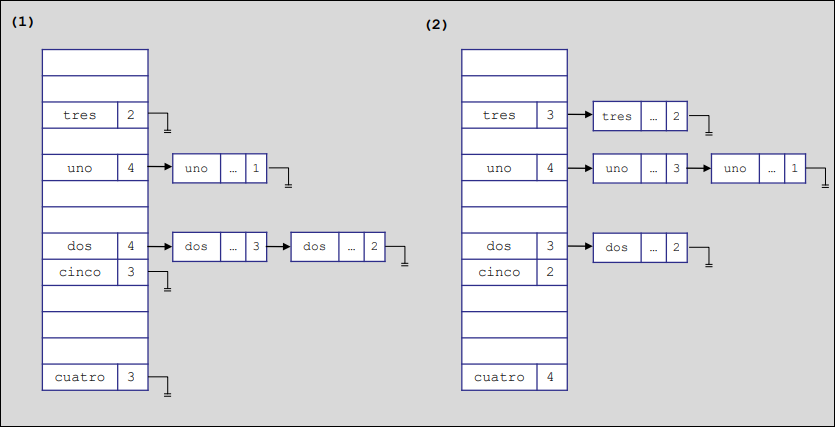
La pila de índices apunta al bloque de esa parte del código. Por ejemplo, en el caso (1), como uno y dos pertenecen al mismo bloque inicial, usan un único índice en la pila. Al entrar en el procedimiento tres y añadir la variable cuatro, se inserta el índice 3 en la pila.
Cuando pasas a un nuevo procedimiento (como de bloque 4 al bloque 5), al estar al mismo nivel, se borra el bloque anterior de la tabla y se mete el nuevo.
El nivel en este caso refleja qué bloques están contenidos dentro de otros (profundidad de anidación), aunque para la gestión de inserción y borrado de esta tabla específica, el nivel puede resultar irrelevante frente a la estructura de bloques.
Tabla de Símbolos con Estrucutra de Árbol
Sección titulada «Tabla de Símbolos con Estrucutra de Árbol»Se mejora la eficiencia estructurando la tabla de símbolos mediante un árbol binario ordenado, y añadiendo un campo a cada registro que indique el nivel al que pertenece el símbolo. Para evitar duplicidades, se usan listas encadenadas.
Admite las siguientes operaciones:
- Inserción. Para insertar un nuevo símbolo, se busca la posición que le corresponde. Si ya hay un registro con el mismo lexema, se comprueba que el campo nivel no tiene el mismo valor que el bloque activo. Si fuese así, habría que indicar un error. En caso contrario, se añade un nuevo nodo a la lista del primero. Si no hay registro, se inserta directamente en el árbol.
- Búsqueda. La propia del árbol binario. Las búsquedas son por lexema.
- Nuevo bloque. Se incrementa en uno el campo de nivel.
- Fin de bloque. Se eliminan los símbolos del bloque: a. Se localizan los registros del árbol del bloque activo. b. Se borran. c. Se decrementa en 1 la variable con el número de nivel.
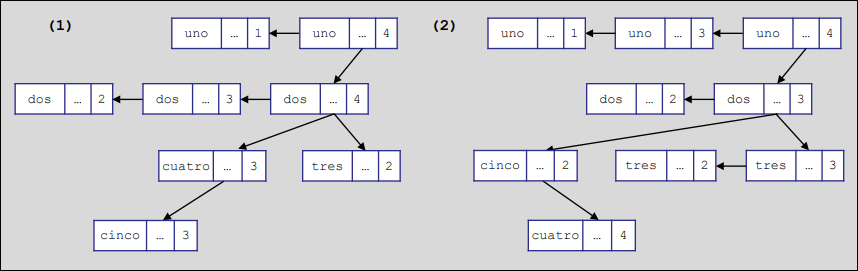
El proceso de construcción comienza con el lexema uno. Al ser un árbol binario de búsqueda basado en el orden alfabético de los lexemas, el siguiente elemento, dos, se inserta a su izquierda (ya que la “d” precede a la “u”). Posteriormente, al insertar tres, el sistema determina que es menor que uno pero mayor que dos, por lo que se posiciona como el hijo derecho del bloque 2.
A medida que el análisis progresa, pueden aparecer colisiones cuando un lexema ya existe en el árbol pero pertenece a un nivel de anidación distinto (por ejemplo, un nuevo dos en un bloque interno). Para gestionar esto, se crea una lista enlazada que cuelga del nodo original; en esta lista, el nodo con el nivel de profundidad más alto se coloca al principio para que sea el primero en ser encontrado en las búsquedas, optimizando así la eficiencia, aunque esto complique posteriormente la eliminación de nodos específicos.
Al finalizar un bloque, como ocurre al cerrar el procedure cinco, el compilador debe realizar una limpieza exhaustiva: debe recorrer la estructura completa para localizar y suprimir todos los nodos cuyo campo de nivel coincida con el bloque activo (nivel 4 en este caso). Esta operación de eliminación resulta ser la más compleja y costosa de mantener, ya que requiere reestructurar el árbol y gestionar las rupturas en las listas enlazadas para no perder la integridad de la tabla.
Tabla de Símbolos con Estructura de Bosque
Sección titulada «Tabla de Símbolos con Estructura de Bosque»La tabla de símbolos con estructura de bosque utiliza un árbol para cada bloque del programa, y una pila de índices de nivel que apuntan a la raíz del árbol de nivel. Esto reduce el problema de las eliminaciones.
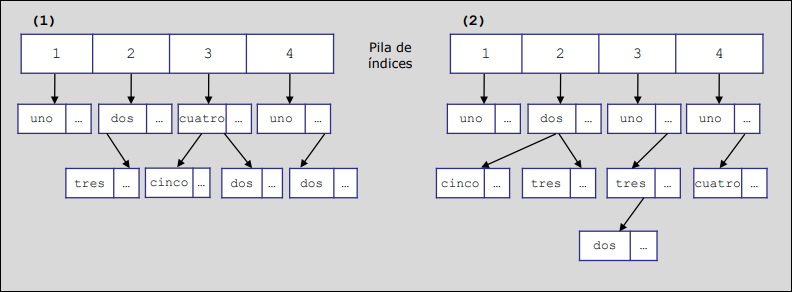
Admite las siguientes operaciones
- Inserción. Consiste en hacer una inserción normal en el árbol del bloque activo.
- Búsqueda. Primero se busca el lexema en el árbol del bloque activo. Si no se encuentra, se busca en el árbol del bloque anterior, y así sucesivamente.
- Nuevo bloque. Cuando empieza la compilación de un nuevo nivel, se crea un nuevo elemento en la pila de índices y una nueva estructura de tipo árbol.
- Fin de bloque. Cuando se termina de compilar un bloque se destruye el árbol asociado y se elimina el último puntero de la pila de índices.
Tabla Hash
Sección titulada «Tabla Hash»Una tabla hash aplica una función matemática al lexema para determinar la posición de la tabla que le corresponde. El inconveniente de las tablas hash es que pueden producirse colisiones cuando dos lexemas quieren ocupar la misma solución. Existen dos soluciones:
- Tablas hash cerradas. Cuando se produce una colisión, se usa una técnica que permita acceder a una posición vacía.
- Tablas hash abiertas. Se utiliza una lista encadenada para resolver las colisiones.
Admite las siguientes operaciones: 1.
- Inserción. Como en una tabla hash normal. Se suelen usar listas de desbordamiento, colocando los símbolos más recientes al principio.
- Búsqueda. Como en una tabla hash normal. En caso de colisión, de busca en la lista de desbordamiento.
- Nuevo bloque. Se almacena el cambio de bloque activo.
- Fin de bloque. Se borran todos los registros correspondientes a ese bloque. Implica recorrer prácticamente toda la tabla. Después se cambia el bloque activo. El truco es hacer una hash para cada cada nivel y tenes una pila que apunte a cada tabla hash.
Análisis de Complejidad
Sección titulada «Análisis de Complejidad»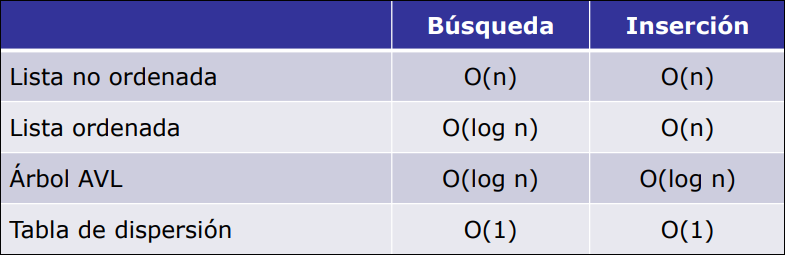
2.6 Tratamiento de Errores
Sección titulada «2.6 Tratamiento de Errores»Cuando en un momento del proceso de compilación se detecta un error:
- Se debe mostrar un mensaje claro y exacto, que permita al programador encontrar y corregir fácilmente dicho error.
- Debe recuperarse del error e ir a un estado que permita continuar analizando el programa en búsqueda de otros errores. Se debe evitar una cascada de errores, o pasar por alto otros.
- No debe retrasar excesivamente el procesamiento de programas correctos.
Errores más característicos de la fase de análisis léxico son:
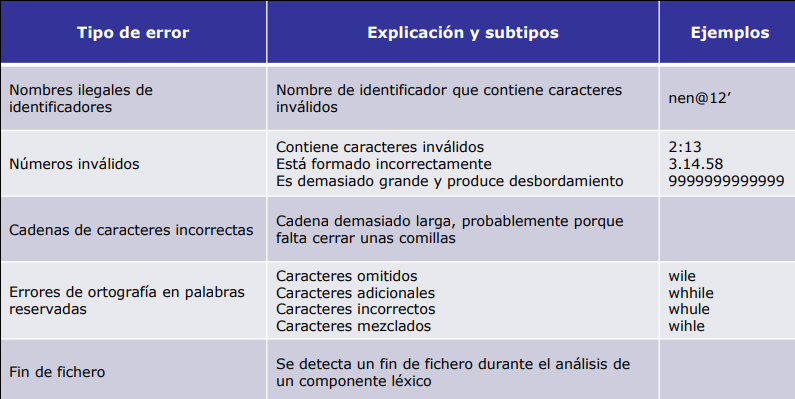
El proceso de recuperación de un error puede suponer la adopción de diferentes medidas:
- Ignorar los caracteres inválidos hasta formar un componente léxico correcto.
- Eliminar caracteres que dan lugar a error.
- Intentar corregir el error:
- Insertar los caracteres que pueden faltar.
- Reemplazar un carácter presuntamente incorrecto por uno correcto.
- Intercambiar caracteres adyacentes.
- Cuidado, intentar corregir un error puede ser peligroso.