Introducción a la Compilación
1.1 Contexto y Evolución
Sección titulada «1.1 Contexto y Evolución»El problema de la traducción de código no es nuevo, surge desde la programación del primer ordenador. Los objetivos son:
- Asimilar la evolución de los lenguajes de programación, motivaciones y caracterísitcas
- Justificar el papel desempeñado por los traductores en la evolución de los lenguajes de programación
- Conocer los distintos tipos de traductores
- Conocer cuáles son las fases del proceso de compilación
- Ser capaz de diseñar el proceso de construcción de un compilador bajo diferentes restricciones de desarrollo.
1.2 Lenguajes de Programación
Sección titulada «1.2 Lenguajes de Programación»Un lenguaje de programación es la herramienta mediante la cual los humanos dan instrucciones a las máquinas. Según su nivel de abstracción:
-
Lenguajes Máquina: son específicos de cada ordenador. Consisten puramente en secuencias de unos y ceros. Son inteligibles para el humano promedio pero nativos para le hardware
-
Lenguajes Ensamblador: también específicos de cada ordenador, pero un paso más arriba, Proporcionan nombres simbólicos para:
- Instrucciones sencillas
- Posiciones de memoria
-
Lenguajes de Alto Nivel: Son independientes de la máquina. Permiten abstracciones complejas como estructuras de control, variables con tipo, procedimientos, recursividad y tipos abstractos de datos.
-
Lenguajes Orientados a Problemas: diseñado para dominios específicos. Su objetivo es reducir el tiempo de programación, mantenimiento y depuración.
1.3 Procesadores de Lenguajes
Sección titulada «1.3 Procesadores de Lenguajes»Un procesador de lenguaje es un software encargado de procesar o traducir un programa fuente. Los dos tipos principales son los compiladores y los intérpretes.
1.3.1 El Compilador
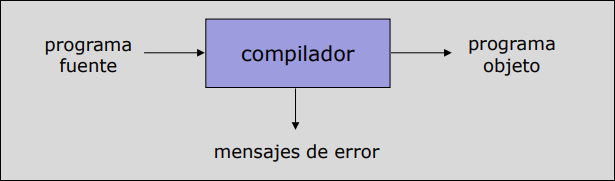
Sección titulada «1.3.1 El Compilador»Es un programa que traduce un programa escrito en un lenguaje fuente a un programa equivalente escrito en un lenguaje objeto.
- Genera un programa objeto (generalmente ejecutable en lenguaje máquina). El lenguaje objeto es un lenguaje máquina.
- Informa de la presencia de errores en todo el código fuente.
El proceso se divide en dos tiempos:
- Tiempo de compilación: Entrada (código fuente) Compilador Salida (código objeto).
- Tiempo de ejecución: El código objeto se ejecuta en la plataforma, recibe datos de entrada y produce resultados.
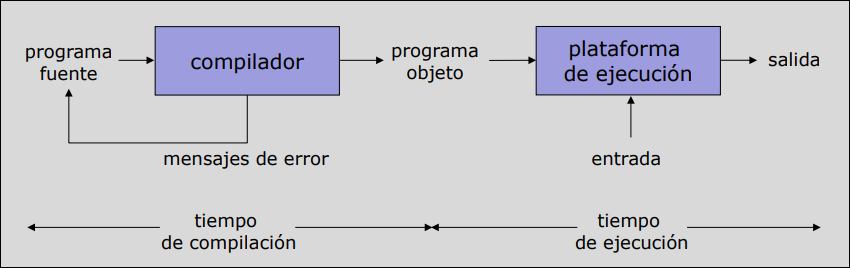
- Ejemplos: FORTRAN, C, PASCAL …
1.3.2 El Intérprete
Sección titulada «1.3.2 El Intérprete»A diferencia del compilador, el intérprete no produce un programa objeto. Aparenta ejecutar directamente cada instrucción del programa fuente utilizando las entradas proporcionadas por el usuario. Traduce y ejecuta instrucción por instrucción.
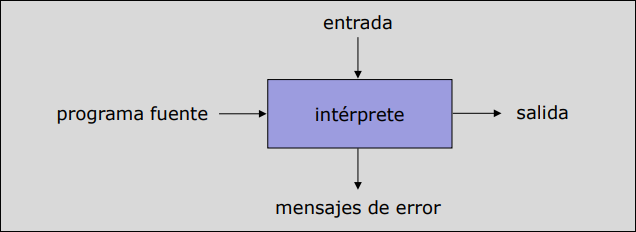
- Ejemplos: BASIC, LISP, PROLOG …
1.3.3 Comparativa
Sección titulada «1.3.3 Comparativa»| Característica | Compiladores | Intérpretes |
|---|---|---|
| Frecuencia de traducción | Se compila una vez, se ejecuta veces. | El programa se traduce cada vez que se ejecuta. |
| Velocidad | La ejecución es más rápida (código nativo). | La ejecución es más lenta (traducción al vuelo). |
| Memoria | Puede requerir más memoria para generar el objeto. | Necesita menos memoria. |
| Gestión de errores | Abarca todo el programa antes de ejecutar. | Los errores saltan durante la ejecución. |
| Interactividad | Baja. | Permite interacción y modificación en tiempo de ejecución. |
| Entorno ideal | Entornos de producción (donde importa la velocidad). | Entornos de desarrollo y experimentación (donde importa la flexibilidad). |
1.3.4 Enfoques Híbridos y Modernos
Sección titulada «1.3.4 Enfoques Híbridos y Modernos»La distinción estricta entre compilador e intérprete se desdibuja en los lenguajes modernos para aprovechar lo mejor de ambos mundos.
Compilador - Intérprete
Sección titulada «Compilador - Intérprete»El proceso se divide en dos fases:
- Compilación a Lenguaje Intermedio: El código fuente se compila a un formato intermedio, no a código máquina real.
- Interpretación (Máquina Virtual): Una máquina virtual interpreta ese código intermedio en el ordenador destino.
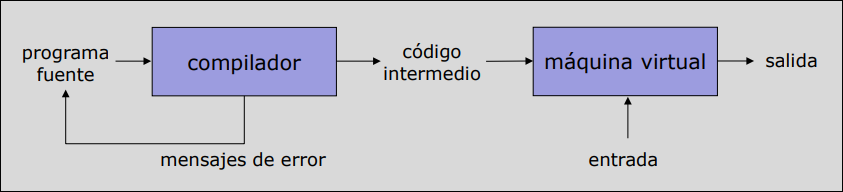
- Ejemplo clásico: Java. El compilador genera bytecode, que luego es interpretado por la JVM (Java Virtual Machine).
Compiladores JIT (Just-In-Time)
Sección titulada «Compiladores JIT (Just-In-Time)»Para mejorar la eficiencia de los sistemas basados en máquinas virtuales o intérpretes, se utilizan los compiladores JIT.
- Funcionamiento: compilan en tiempo de ejecución fragmentos del código intermedio directamente a código objeto.
- Ventaja: mejora drásticamente la velocidad de ejecución.
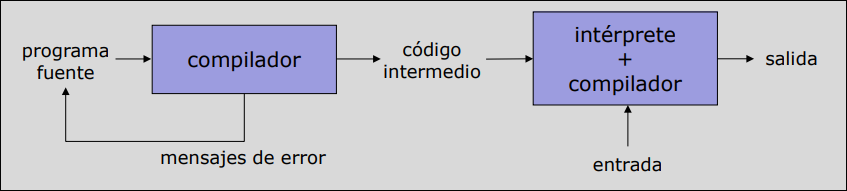
- Ejemplos: JAVA, PHP, PYTHON …
1.4 El proceso de traducción
Sección titulada «1.4 El proceso de traducción»A menudo pensamos que el compilador hace todo el trabajo, pero es una pieza dentro de una cadena de herramientas más grande que transforma el código fuente en un ejecutable final.
La secuencia completa es la siguiente:
-
Preprocesador: recibe como entrada el programa fuente, se encarga de preparar el código antes de compilar. Incluye ficheros, elimina comentarios, expande macros y activa directivas de preprogramación. Produce un programa fuente modificado.
-
Compilador: traduce el código modificado y produce el programa destino en lenguaje ensamblador
-
Ensamblador: traduce el ensamblador a código binario. Produce como salida código máquina relocalizable (aún no está listo para ejecutarse porque le faltan referencias externas).
-
Enlazador / Cargador (Linked/Loader): Añade bibliotecas externas, permitiendo la reutilización de código. Une todas las piezas y produce el código máquina destino (el ejecutable final).
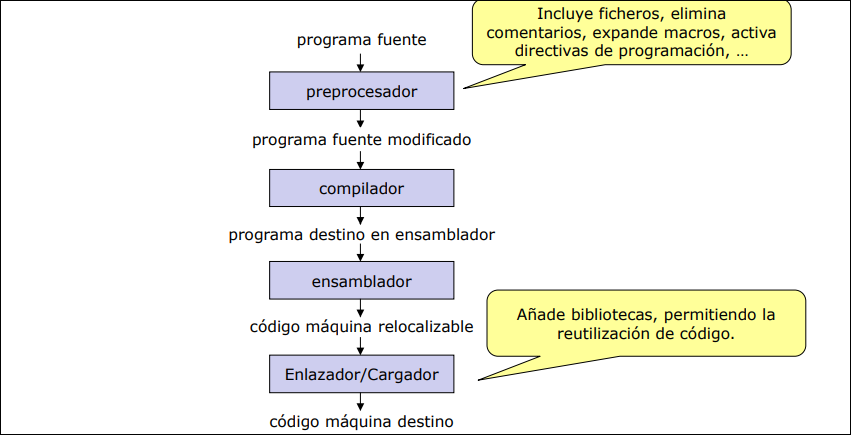
1.5 Estructura Interna de un Compilador
Sección titulada «1.5 Estructura Interna de un Compilador»El compilador se divide en dos grandes fases que actúan como un puente entre el lenguaje humano y el de la máquina:
- Fase de Análisis (Front-end): entiende qué dice el programa. Descompone el código fuente y crea una representación intermedia.
- Fase de Síntesis (Back-end): construye el programa objeto. Genera el código destino a partir de la representación intermedia.
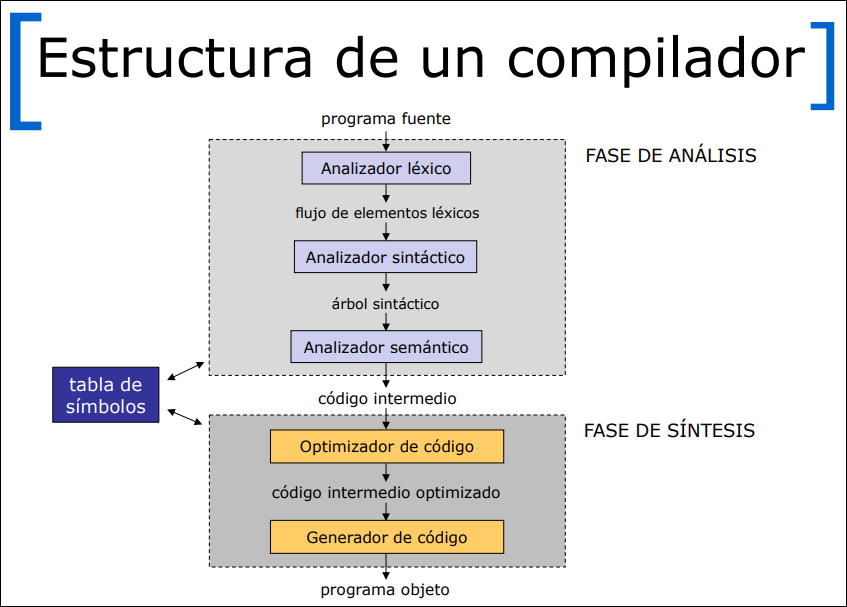
Si tenemos lenguajes fuente y plataformas, crear un compilador para cada combinación requeriría compiladores. La solución es usar un Código Intermedio:
- Se crea una única fase de análisis para cada lenguaje
- Se crea una única fase de síntesis para cada plataforma
- El código intermedio sirve de puente universal. Esto reduce drásticamente el esfuerzo de desarrollo.
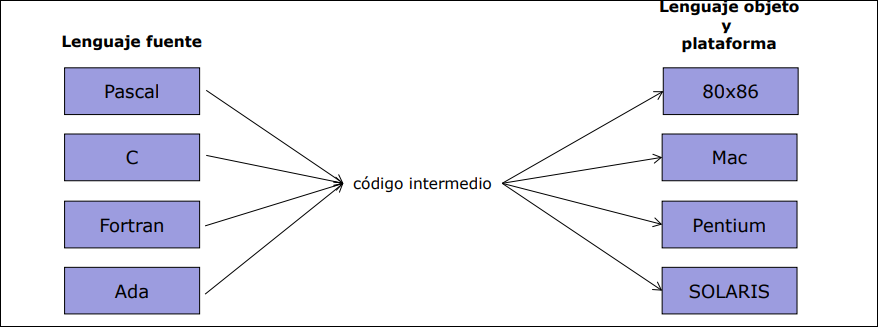
1.5.1 Fases del Compilador
Sección titulada «1.5.1 Fases del Compilador»A continuación se detallan las etapas por las que pasa el código, usando el ejemplo de la operación: posición = inicial + velocidad * 60
Analizador Léxico (Scanner)
Sección titulada «Analizador Léxico (Scanner)»Lee el flujo de caracteres del programa fuente y los agrupa en secuencias con significado llamadas componentes léxicos (tokens).
- Ejemplo: Identifica
posicion, el símbolo=, el identificadorinicial, etc. - Salida: Un flujo de tokens.

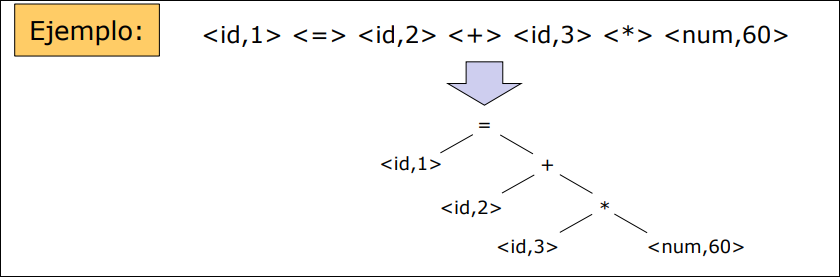
Analizador Sintáctico (Parser)
Sección titulada «Analizador Sintáctico (Parser)»Recibe los tokens y crea una estructura jerárquica (generalmente un árbol) que describe la estructura gramatical del código.
- Árbol sintáctico: cada nodo interior es una operación y los hijos son los argumentos.
- Ejemplo: Crea un árbol donde
*(multiplicación) es hijo de+(suma), respetando la precedencia matemática.
Analizador Semántico
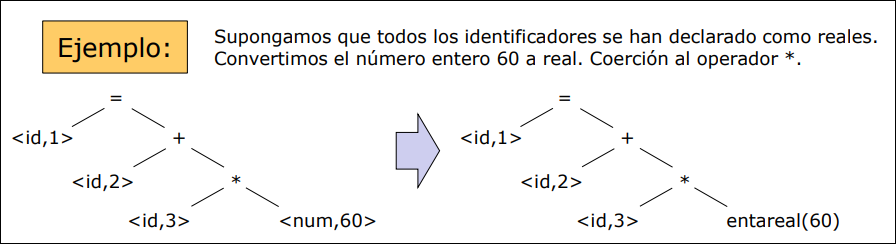
Sección titulada «Analizador Semántico»Revisa el árbol sintáctico para comprobar la consistencia semántica (el significado). Su tarea principal es la verificación de tipos.
- Coerción: si el lenguaje lo permite, el analizador puede convertir tipos automáticamente.
- Ejemplo: En
velocidad * 60, sivelocidades un número real y60es entero, el analizador convierte el60a real (entareal(60)) para que la operación sea válida.
Generador de Código Intermedio
Sección titulada «Generador de Código Intermedio»Traduce el árbol a un código para una máquina abstracta. Debe ser fácil de producir y traducir.
- Código de tres direcciones: es una representación común donde cada instrucción tiene máximo 3 operandos.
- Ejemplo:
temp1 = entareal(60)temp2 = id3 * temp1temp3 = id2 + temp2id1 = temp3Optimizador de Código
Sección titulada «Optimizador de Código»Intenta mejorar el código intermedio para que sea más rápido o consuma menos recursos, sin cambiar el resultado.
- Ejemplo: El optimizador se da cuenta de que la conversión de
60a60.0se puede hacer de una vez durante la compilación, ahorrando una instrucción:
temp1 = id3 * 60.0 (Ahorramos la instrucción de conversión)id1 = id2 + temp1Generador de Código
Sección titulada «Generador de Código»Traduce el código intermedio optimizado al lenguaje destino (código máquina o ensamblador). Aquí se asignan los registros de memoria reales de la CPU.
- Ejemplo:
LDF R2, id3 ; Cargar id3 en Registro 2MULF R2, R2, #60.0 ; Multiplicar R2 por 60.0LDF R1, id2 ; Cargar id2 en Registro 1ADDF R1, R1, R2 ; Sumar R1 y R2STF id1, R1 ; Guardar resultado en id11.5.2 La Tabla de Símbolos
Sección titulada «1.5.2 La Tabla de Símbolos»Es una estructura de datos esencial que se usa durante todas las fases del compilador.
Se encarga de registrar los nombres de los elementos del programa (variables, procedimientos) junto con sus atributos. Atributos almacenados:
- De variables: Dirección de memoria, tipo, dimensión, alcance, precisión, estado de inicialización.
- De procedimientos: Número y tipo de argumentos, modo de paso (valor o referencia), tipo de retorno, si es recursivo.
1.6 Construcción de Compiladores
Sección titulada «1.6 Construcción de Compiladores»Para definir correctamente la construcción de un compilador, es imprescindible identificar tres lenguajes distintos:
- El lenguaje fuente: El lenguaje que el compilador traduce (entrada).
- El lenguaje objeto: El lenguaje al que se traduce y la plataforma donde se ejecutará (salida).
- El lenguaje de implementación: El lenguaje en el que está escrito el propio programa compilador.
Ejemplo: Si tenemos un ejecutable en un PC que traduce Pascal a código máquina:
- Fuente: Pascal.
- Objeto: Código máquina del PC.
- Implementación: Código máquina del PC (porque ya es un ejecutable).
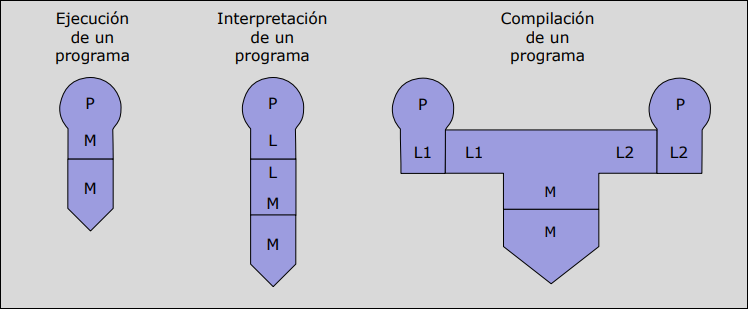
1.6.1 Diagramas de Tombstone
Sección titulada «1.6.1 Diagramas de Tombstone»Son una herramienta visual de alto nivel que facilita el diseño y la comprensión de cómo interactúan compiladores, intérpretes y máquinas. Hay cuatro tipos de piezas.
Compiladores (Forma de T)
Sección titulada «Compiladores (Forma de T)»Representan la traducción de un lenguaje a otro.

Programas
Sección titulada «Programas»Representan un programa escrito en un lenguaje .

Máquinas
Sección titulada «Máquinas»Representan el hardware o sistema operativo base.

Intérpretes
Sección titulada «Intérpretes»Representa el intérprete del lenguaje escrito en .

1.6.2 Reglas de Unión de Diagramas
Sección titulada «1.6.2 Reglas de Unión de Diagramas»La regla de oro para conectar estas piezas es: Dos diagramas se pueden unir si en la unión los lenguajes son iguales. Se pueden dar tres situaciones básicas:
- Ejecución: Un programa escrito en código máquina ( en ) se coloca sobre la máquina ().
- Interpretación: Un programa ( en ) se coloca sobre un intérprete ( en ), y este sobre la máquina ().
- Compilación: Un programa fuente entra en un compilador, y este genera un programa objeto.
1.6.3 Estrategias Avanzadas de Construcción
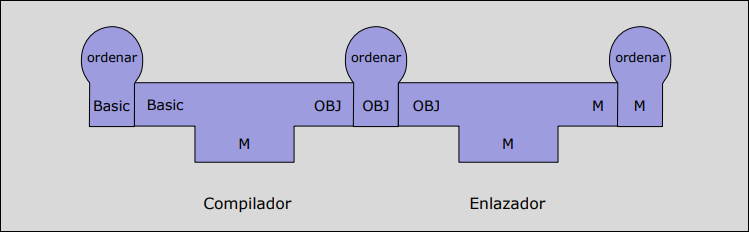
Sección titulada «1.6.3 Estrategias Avanzadas de Construcción»Compilador- Enlazador
Sección titulada «Compilador- Enlazador»Divide la traducción en dos fases para permitir desarrollar múltiples compiladores para múltiples plataformas reutilizando trabajo.
- Fase 1 (Compilador): Traduce Fuente Código Intermedio (OBJ)
- Fase 2 (Enlazador): Traduce Código Intermedio (OBJ) Máquina ().
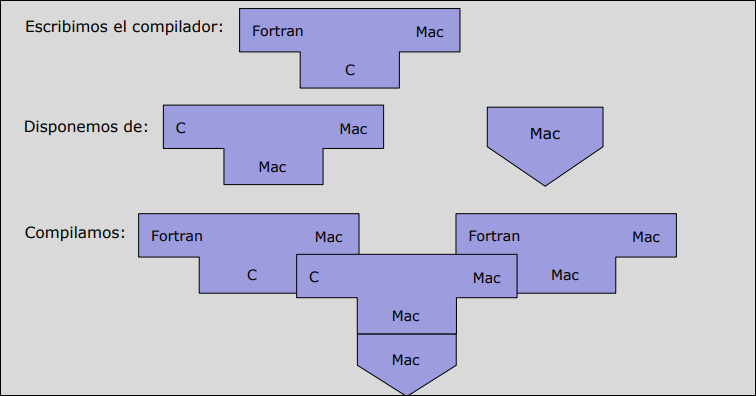
Compilación Cruzada
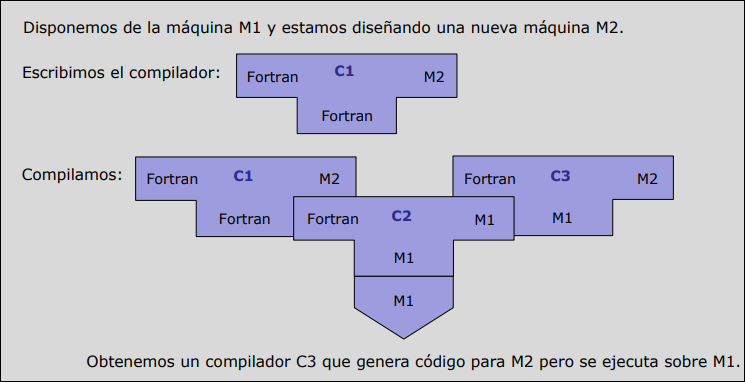
Sección titulada «Compilación Cruzada»Es la técnica que permite crear ejecutables para una máquina diferente a la que estamos usando para desarrollar.
- Escenario: Estamos en una máquina y queremos crear un compilador que genere código para una máquina nueva .
El proceso consta de dos fases:
-
Fase 1: Usamos un compilador existente en para compilar nuestro nuevo compilador.
- Resultado (): Un compilador que corre en M1 pero genera código para M2. (A esto se le llama compilador cruzado).
-
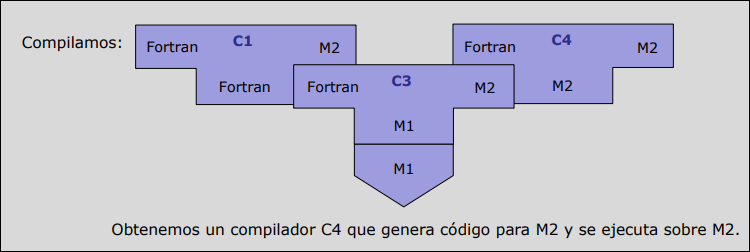
Fase 2: Usamos el compilador cruzado () para re-compilar el código fuente del nuevo compilador.
- Resultado (): Un compilador que corre en M2 y genera código para M2.
Bootstrapping
Sección titulada «Bootstrapping»Es una técnica de “autosuficiencia” o “auto-arranque”.
- Definición: Construir un compilador de un lenguaje usando una versión reducida del propio lenguaje, o escribir el compilador en el mismo lenguaje que compila.
- Autocompilador: Es aquel capaz de compilar su propio código fuente.
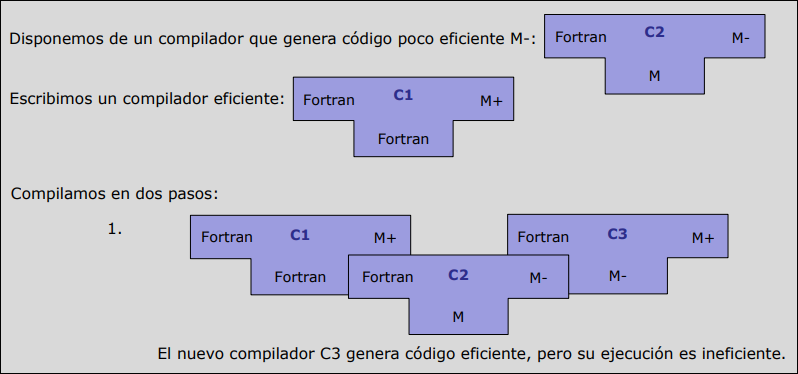
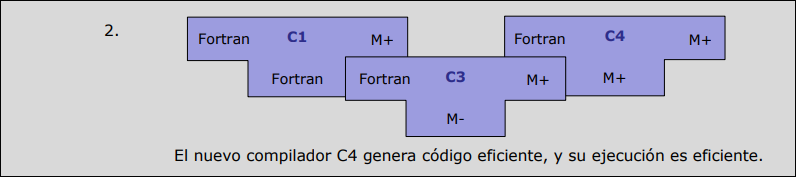
Caso práctico: Mejora de eficiencia (De M- a M+) Si tienes un compilador que funciona pero genera código ineficiente (), y escribes uno nuevo que genera código eficiente (), usas bootstrapping para optimizarlo:
-
Paso 1: Compilas el código del nuevo compilador () usando el viejo ().
- Resultado (): El compilador genera código eficiente, pero el compilador en sí mismo es lento (porque fue creado por el viejo).
-
Paso 2: Usas para compilar otra vez el código fuente de .
- Resultado (): Ahora tienes un compilador que genera código eficiente y se ejecuta eficientemente.
Compilador-Intérprete
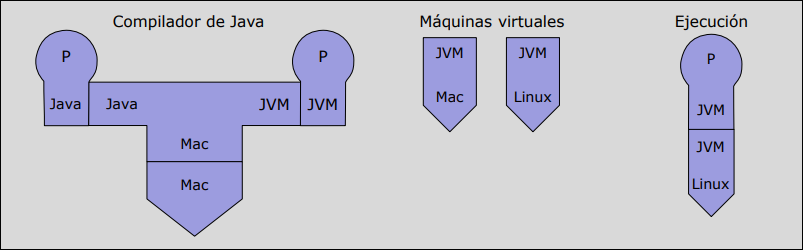
Sección titulada «Compilador-Intérprete»Es la colaboración para lograr portabilidad (como en Java).
- Se compila a un lenguaje intermedio ().
- Se usa un intérprete de escrito en la máquina .
- Concepto Clave: La unión del intérprete + la plataforma de ejecución se denomina Máquina Virtual.

1.7 Aplicaciones
Sección titulada «1.7 Aplicaciones»- Edición de textos con formato. Por ejemplo, LaTeX.
- Reconocimiento de patrones: tanto de texto, como reconocimiento del habla o visión por computadora.
- Desarrollo de editores de lenguajes estructurados. Por ejemplo, Xemacs. o Cálculo simbólico. Por ejemplo, MAPLE, SCILAB,…
- Diseño de circuitos integrados, mediante lenguajes como Verilog y VHDL.
- Traducción binaria. Para portar software entre plataformas.
- Simulación de arquitecturas hardware, para distintos conjuntos de datos, antes de su fabricación.