Resumen COMDIS
Un paradigma es un patrón o modelo. Una aplicación distribuida necesita que dos o más procesos independientes intercambien información y necesita sincronización, hay que coordinar cuándo se envían y reciben. Paradigmas:
- Paso de Mensajes: se basa en operaciones de entrada/salida similares a escribir en un archivo mediante el uso de primitivas básicas (
sendyreceive). - Cliente Servidor: es el modelo más conocido y asimétrico, donde hay una clara división de jerarquía. Los nodos que intervienen tienen funciones, objetivos y responsabilidades diferentes. El cliente adopta un rol activo donde inicia la comunicación y realiza peticiones al servidor, mientras que el servidor tiene un rol pasivo esperando pasivamente a recibir peticiones de los clientes para poder procesarlas. El objetivo es proporcionar una arquitectura que pueda ofrecer servicios facilitando la sincronización de eventos y permitiendo que los clientes sean ligeros centralizando recursos en el servidor.
- P2P: es una arquitectura simétrica, homogénea y descentralizada. No hay una división jerárquica como en cliente-servidor, los nodos llevan a cabo las mismas funciones y tienen las mismas responsabilidades. Colaboran para conseguir objetivos comunes. Además al no tener todos los recursos centralizados en un único servidor no existe un único punto de fallo y si falla un nodo los demás pueden seguir colaborando.
- RPC: abstracción que permite llamar a una función que está en otro ordenador. Emplea stubs generados con
rpcgen - RMI: evolución de RPC orientada a objetos. En RPC llamas a funciones y en RMI invoca a métodos de un objeto que vive en otra máquina.
- ORB: traductor universal independiente de plataforma y lenguaje, el estándar más famoso es CORBA.
- Sistemas de Mensajes: se caracterizan por el desacomplamiento temporal y espacial, permite que dos procesos se comuniquen sin tener que estar ambos de forma activa en la comunicación (permite la comunicación asíncrona).
- Modelo punto a punto: se deja un mensaje en la cola y el receptor lo recoge
- Modelo publica suscribe: se basa en eventos
El api de sockets es la interfaz de programación estándar para la comunicación entre procesos (IPC), es el nivel de asbtracción más bajo que nos ofrece el sistema operativo.
TCP: En el modelo Stream, la comunicación es exclusiva entre dos procesos conectados.
//parte del servidorSocketServer ss = new SocketServer(puerto);Socket s = ss.accept();DataInputStream in = new DataInputStream(s.getDataInputStream());DataOutputStream out = new DataOutputStream(s.getDataOutputStream());out.writeByte(5);System.out.println(in.getByte());
//parte del clienteSocket s = new Socket ("ipservidor", puerto);DataInputStream in = new DataInputStream(s.getDataInputStream());DataOutputStream out = new DataOutputStream(s.getDataOutputStream());out.writeByte(5);System.out.println(in.getByte());UDP: En el modelo datagrama no hay conexión persistente. Cada paquete es independiente y lleva consigo la diercción de destino. Son como cartas independientes.
//parte del emisorDatagramSocket ds = new DatagramSocket();InetAddress receptor = InetAddress.getByName("ip");byte[] data = "Hola".getBytes();DatagramPacket dp = new DatagramPacket(data, data.length, receptor, puerto); //permite enviards.send(dp);
//parte del receptorDatagramSockets ds = new DatagramSocket(puerto);byte[] buffer = new byte[1024];DatagramPacket dp = new DatagramPacket(buff, buff.length); //permite recibirds.receive(dp);Por defecto receive y read son bloqueantes, por lo que impiden que hilo de ejecución avance y puede provocar que el programa se quede bloqueado de forma indefinida. Por ello usamos el método socket.setSoTimeout(int milisegundos) donde si se ha llamado a una operación bloqueante y no se ha recibido un mensaje, tras transcurrir el periodo de tiempo especificado en el método, se lanza una excepción que permite retomar el control.
Broadcast implica difusión a todos los dispositivos de una red mientras que multicast implica la difusión a todos los dispositivos de una subred.
Existen 2 formas de crear un hilo:
- Heredando de Thread:
public class MiHilo extends Thread(){ @Override public void run(){ ... }}
Thread hilo = new MiHilo();hilo.start();- Implementando Runnable:
public class MiHilo implements Runnable(){ @Override public void run(){ ... }}
MiHilo h = new MiHilo();Thread hilo = new Thread(h);hilo.start();Para que un código sea thread-safe es importante proteger regiones críticas empleando cerrojos:
- Bloque sincronizado: protege un fragmento de código usando un objeto como cerrojo
synchronized(objetoCerrojo) { // Sección crítica}- Método sincronizado: esto usa como propio cerrojo al objeto, por lo que lo bloquea y no se puede usar ningún otro método mientras se usa el método sincronizado
public synchronized void metodo() { ... }Además tenemos los siguientes métodos para poder manejar a los hilos:
wait(): El hilo suelta el cerrojo y se duerme hasta ser avisado. Si se interrumpe, lanzaInterruptedException.notify(): Despierta a un hilo aleatorio que esté esperando en ese objeto.notifyAll(): Despierta a todos los hilos esperando (más seguro para evitar bloqueos indefinidos).start(): Inicia la ejecución del hilo.sleep(long ms): Pausa el hilo actual el tiempo indicado.join(): Hace que el hilo actual espere hasta que el hilo al que se llama termine (ej. elmainespera a los trabajadores).currentThread(): Devuelve la referencia al hilo que está ejecutando esa línea de código.
Java RMI es la evolución Orientada a Objetos de RPC. Java RMI es por naturaleza multihilo. Cada solicitud de un cliente se procesa a través de un hilo independiente en el servidor, es importante que la implementación del objeto remoto sea Thread Safe. Para construir una app RMI disponemos de una metodología estricta basada en interfaces.
public interface InterfazRemota extends Remote{ public String métodoRemoto() throws RemoteException;}Todos los métodos remotos deben lanzar RemoteException porque la red puede caerse, el servidor no existir o el stub perderse. Java obliga al programador a manejar estos fallos explícitamente.
public class ObjetoServidor implements InterfazRemota extends UnicastRemoteObject{
public ObjetoServidor() throws RemoteException{ super(); }
@Override public String métodoRemoto() throws RemoteException{ System.out.println("HOla"); }}El objeto servidor es aquel que implementa las operaciones definidas por la interfaz remota.
public class ServidorObjetos{ public static void main(String[] args){ try{ LocateRegistry.createRegistry(puerto); ObjetoServidor os = new ObjetoServidor(); Naming.rebind("rmi://ip:puerto/Servicio", os); }catch (Exception e){ e.printStackTrace(); } }}El servidor de objetos es el encargado de iniciar el registro RMI, instanciar al objeto servidor y publicarlo en el registro.
En el lado de cliente simplemente hacemos un cast a la interfaz remota de la referencia que devuelve el método Naming.lookup(url).
public class Cliente{ public static void main(String[] args){ try{ InterfazRemota ir = (InterfazRemota) Naming.lookup("rmi://ip:puerto/Servicio"); ir.métodoRemoto(); }catch(Exception e){ e.printStackTrace(); } }
}A la hora de desarrollar una aplicación RMI simple necesitamos la siguiente colocación de archivos:
- Servidor:
InterfazRemota.class,ObjetoServidor.class,ServidorObjetos.class,Skell.class - Cliente:
InterfazRemota.class,Cliente.class,Stub.class.
El stub.class y skell.class son simplemente los proxies de cliente y de servidor generados tras ejecutar rmic ObjetoServidor.class. Cuando un cliente quiere ejecutar un método, lo ejecuta sobre el stub, el stub realiza el marshalling (serialización) convirtiendo los argumentos del método en un flujo de bytes que envía a través de la red. El skeleton realiza el unmarshalling (deserialización), reconstruye los argumentos originales a partir de los bytes recibidos y llama al método en el objeto servidor real. Para retornar los valores del método se realiza el proceso contrario.
El stub downloading soluciona el problema de tener que redistribuir de forma manual el Stub.class cuando se realizaba un cambio en la implementación del objeto remoto. Para ello almacenamos el stub en un servidor http, y cuando el cliente ve que no tiene el stub lo descarga automáticamente del servidor http. Para esto a la hora de arrancar el servidor de objetos tenemos que indicar varias propiedades:
- Codebase: indica la url del servidor http.
- Hostname: indica la ip pública del servidor
- Policy: es el archivo de permisos de seguridad
java -Djava.rmi.server.codebase=http://www.miservidor.com/clases/ -Djava.rmi.server.hostname=mi.ip.publica -Djava.security.policy=java.policy
El gestor de seguridad es imprescindible porque al usar stub downloading estás ejecutando código descargado de una red externa, lo que supone un gran riesgo. Por ello usamos System.setSecurityManager(new RMISecurityManager()); encargado de gestionar la seguridad consultando el archivo java.policy. En este archivo definimos los permisos que va a tener la aplicación (conectarse al registro rmi en el puerto 1099, descargar stubs mediante el puerto 80 y conexiones efímeras).
En java RMI existe la posibilidad de realizar una comunicación bidireccional (RMI Callbacks) para solucionar el problema de que el cliente sondee de forma constante al servidor saturando la red (polling). Para implementar esto necesitamos que el objeto servidor tenga un array donde almacene las referencias remotas de los clientes y un método para poder registrarlos.
public class ObjetoServidor implements InterfazRemotaServidor extends UnicastRemoteObject{ private vector<InterfazRemotaCliente> clientes;
public ObjetoServidor throws RemoteException{ super(); }
@Override public addClienteCallback(INterfazRemotaCliente c){ clientes.add(c) }
private llamarCliente(){ clientes.get(0).serllamado(); }}La colocación de archivos con RMI Callback es:
- Servidor:
IntServer.class,ImplServer.class,Server.class,IntClient.class,StubClient.class,SkellServer.class. - Cliente:
IntClient.class,ImplCliente.class,Client.class,IntServer.class,StubServer.class,SkellClient.class.
Por último, para poder transmitir objetos a través de la red mediante el uso de rmi estos deben de ser serializables, serializar es un mecanismo que permite convertir un objeto en una secuencia de bytes para que se pueda enviar por la red. Para enviar un objeto como argumento en RMI debe implementar la interfaz java.io.Serializable, si no lo hace, RMI lanzará una excepción al intentar enviarlo. Además todos los atributos del objeto deben de ser serializables (primitivos, strings o implementar serializable). Si hay datos que no quieres enviar debes marcarlos con la palabra clave transient.
- Napster: tenía una arquitectura híbrida dónde consultabas a un servidor central quién tenía el archivo deseado y después obtenías la ip del usuario deseado y te conectabas al cliente para descargarlo. El problema era que el servidor era un único punto de fallo, un cuello de botella.
- Gnutella: P2P puro, dónde las consultas se realizaban por inundacióny el mensaje de petición tenía un TTL máximo para saltar entre nodos. El problema era que había un tráfico de red y no garantizaba encontrar el archivo.
- Kaaza/Fastrack: introducen el concepto de superpeers, nodos con un nivel jerárquico superior al resto por su potencia y buena conexión, que actuaban como pequeños servidores napster. Los nodos normales subían sus listas de archivos al Super-peer y le preguntaban a él
- Freenet: en los anteriores sistemas distribuidos la identidad no er anónima, pero aquí si que lo era madiante un mecanismo de descubrimiento incremental dónde la repuesta viaja siguiendo el camino inverso a la consulta. Es imposible saber si un nodo está iniciando o consumiendo una petición o simplemente reenviando la de otro.
- El problema del gorrón consiste en que la mayoría de usuarios no subían nada y solo descargaban.
El problema de gnutella y otros predecesores P2P era que no garantizaban encontrar el archivo aunque exista o era ineficientes. Por ello surgen las DHT (Tablas Hash Distribuidas), que son un tipo de sistema distribuido descentralizado que ofrece un servicio de búsqueda similar a una tabla hash dónde los datos están distribuidos entre los nodos de la red, cada nodo es responsable de un pequeño rango de claves y cualquier nodo puede encontrar de forma eficiente a otro nodo que tiene el dato que busca, sin necesidad de un servidor central. Tenemos los siguientes algoritmos de DHT:
- Chord: los nodos de la red forman un anillo lógico donde cada archivo se almacena en el nodo cuyo identificador sea igual o inmediatamente mayor al identificador del archivo. Además cada nodo tiene una tabla de dedos en la que contiene las direcciones de los nodos ubicados a distancias potencia de 2. El problema es que es un anillo lógico y no físico por lo que se puede producir mucha latencia.
- Pastry: intenta solucionar el problema de chord, enrutando los nodos mediante claves parciales, dónde si soy el nodo
abcdey busco alghjk, primero busco al nodo que empiece porgy si hay varios candidatos escojo al más cercano geográficamente. - Can: ignora el anillo y códigos y trata a la red como un mapa de coordenadas gigante, donde si estás en el (0,0) y quieres enviar un archivo al (1,1), le pasa el mensaje a tu vecino de la derecha arriba.
El problema de las arquitecturas RPC, CORBA, RMI y DCOM es que se intentaban conectar a puertos aleatorios poco comunes que eran bloqueados por los firewalls y además se requería que ambas máquinas a comunicar usasen la misma tecnología o lenguaje.
Después esto dio lugar al concepto de Tunneling a través de Java Servlets. La técnica consistía en encapsular las peticiones de datos dentro de tráfico HTTP estándar, permitiendo que atraviese firewalls. Los servlets actuaban como pequeños programas en el servidor que escuchaban peticiones en el puerto 80. Sin embargo el html no está estructurado y requiera que el cliente al otro lado parsee de forma manual la información estructurado.
SOA es un paradigma para construir sistemas distribuidos basado en la integración de servicios autónomos, débilmente acoplados e interoperables. Permite que aplicaciones desarrolladas en tecnologías heterogéneas se comuniquen mediante estándares abiertos, combinando el transporte universal (HTTP) con un formato de datos estructurado (XML).
Está formada por 3 elementos:
- Proveedor: crea y expone el servicio
- Registro: directorio donde se registran los servicios para ser encontrados
- Consumidor: buscar y usa el servicio
Funcionamiento:
- El proveedor crea el servicio y su contrato (WSDL) accesible vía URL
- Registra el servicio en el directorio UDDI para que sea visible
- El consumidos busca en el registro y obtiene la url del wsdl
- Con el wsdl el consumidor genera automaticamente stubs y proxies
- Por utlimo se lanza la petición encapsulada en SOAP a través de http
WSDL es un archivo XML jerárquico divido en dos bloques:
- Descripción abstracta: se define la interfaz funcional sin importar el lenguaje de proramación, define los tipos de datos, los tipos de mensajes, el portType que funciona como un agrupador estilo interfaz de java y las operaciones, que definen la accion conectando un mensaje de entrada con uno de salida.
Jerarquía:
typescomponenmessageusados enoperationagrupados enportType.
- Descripción concreta: define la conexión física. Indica el
binding, que es el tipo de protocolo asociado alportType, normalmente SOAP sobre HTTP.serviceque agrupa a los puertos yportque una unbindinga un puerto.
SOAP es un estándar XML para invocar servicios, no tiene estado y es unidireccional y síncrono. Todo el mensaje SOAP es un XML con 3 partes:
- Envelope: raíz obligatoria que encapsula todo
- Header: es opcional contiene metadatos, puede ser procesado por nodos intermediarios.
- Body: es la carga útil con los datos de negocio. Solo para el destinatario final.
Los atributos de la cabecera permiten controlar el flujo a través de intermediarions:
role: define qué nodo debe leer la cabecera (next,ultimateReceiver)mustUnderstand: si estruey el nodo no entienda la etiqueta, debe fallar. Además los mensajes SOAP pueden tener dos estructuras:- Document: le envías datos
- RPC: pides que se ejecute una función, simula una llamada a código.
El viaje del mensaje desde tu código Java hasta el servidor remoto:
- Código Cliente: Llama al método local (
stub.sumar(5,5)). - Stub Cliente: Delega en el Motor SOAP (JAX-WS).
- Motor SOAP: Serializa a XML (SOAP) y lo pasa al Cliente HTTP.
- Red: El mensaje viaja por HTTP (POST).
- Router SOAP (Servidor): Recibe el XML, lo parsea y decide a qué servicio llamar.
- Skeleton/Stub Servidor: Deserializa el XML a objetos Java.
- Implementación: Se ejecuta el código real (
public int sumar...).
//interfazpackage com.ejemplo;
@WebServicepublic interface Calculadora{ @WebMethod int sumar(int a, int b);}//implementaciónpackage com.ejemplo;
@WebService(endpointInterface="com.ejemplo.Calculadora") //esto sirve para que solo se publiquen los métodos efinidos en la interfaz y no los de la implementación.public class CalculadoraImpl implements Calculadora{ public int sumar(int a, int b){ return a+b; }}// publicadorpublic class Publicador{ public static void main(String[] args){ Endpoint.publish("http:localhost_8080/miCalculadora", new CalculadoraImpl()); }}/*Endpoint.publish- Arranca: Inicia un servidor HTTP ligero interno en el puerto 8080.- Genera: Crea el WSDL dinámicamente en memoria.- Expone: Habilita la escucha de peticiones SOAP en esa URL.*///clientepublic class Cliente { public static void main(String[] args) { try { // 1. URL del WSDL (El Manual) URL wsdlURL = new URL("http://localhost:8080/miCalculadora?wsdl");
// 2. QName (Identificador Único: Namespace + ServiceName) QName qname = new QName("http://ejemplo.com/", "CalculadoraImplService");
// 3. Crear la Fábrica (Service) Service service = Service.create(wsdlURL, qname);
// 4. Obtener el Proxy (Stub) Calculadora proxy = service.getPort(Calculadora.class);
// 5. Invocación Remota (Marshalling -> Red -> Unmarshalling) System.out.println("Resultado: " + proxy.sumar(10, 20));
} catch (Exception e) { e.printStackTrace(); } }}| Método | Función Técnica |
|---|---|
URL(...?wsdl) | Apunta a la ubicación del contrato. Sin el ?wsdl al final, no funciona. |
QName | Nombre Cualificado. Identifica al servicio exacto dentro del XML del WSDL. Se forma con el TargetNamespace (paquete invertido) y el ServiceName. |
Service.create() | La Fábrica. Descarga el WSDL, lo valida y prepara la conexión. |
getPort() | El Proxy (Stub). Crea un objeto local falso. Convierte tus llamadas Java (.sumar) en mensajes XML SOAP (Marshalling) y los envía por HTTP. |
Un sistema de mensajes o MOM es un middleware que permite el desacomplamiento temporal y estructural mediante una conexión única al MOM. RabbitMQ es un middlware de mensajería que emplea AMQP, que es un protocolo asíncrono que garantiza el envío fiable de mensajes en colas seguras hasta que el receptor se conecte o cumpla los criterios para recibirlo.
Cuando el emisor envía un mensaje a un consumidor este siempre pasa por un exchange que decide a qué cola mandar el mensaje en base a unos criterios:
- Default: la routing key del mensaje es el nombre de la cola destino, si coincide el exchange envía el mensaje a esa cola.
- Fanout: el exchange ignora la routing key del mensaje y envía el mensaje a todas las colas conectadas al exchage.
- Direct: el exchange compara la rounting key con la binding key de la cola para saber si puede enviarla a esa cola.
- Topic: similar a direct pero permite coincidencias parciales entre colas mediante el uso de wildcards. Un mensaje con clave
a.b.cpodría entrar a una cola que escuchaa.*oa.b.# - Header: ignora la routing key e inspecciona los metadatos para compararlos con la binding key.
//productorConnectionFactory cf = new ConnectionFactory();cf.setHost("localhost");try{ Connection cn = cf.newConnection(); Channel ch = cn.createChannel(); //queueDeclare(nombreCola, durable, exclusive, autoDelete, arguments); ch.queueDeclare("COLA", false, false, false, null);
String msg = "HOla"; //basicPublish(exchange, routingKey, metadatos,body); ch.basicPublish("", "COLA", null,msg.getBytes());}//consumiedorConnectionFactory cf = new ConnectionFactory();cf.setHost("localhost");try{ Connection cn = cf.newConnection(); Channel ch = cn.createChannel(); ch.queueDeclare("COLA", false, false, false, null);
DeliverCallback deliverCallback = (consumerTag, delivery) -> { String message = new String(delivery.getBody(), "UTF-8"); System.out.println("Recibido: " + message); };
// basicConsume(queue, autoAck, deliverCallback, cancelCallback) channel.basicConsume("COLA", true, deliverCallback, consumerTag -> { });
}Tipos de exchange:
- Fanout:
// 1. Declaramos el exchange de tipo FANOUTchannel.exchangeDeclare("exchange_deportes", "fanout");
// 2. Publicamos.String mensaje = "GOL DEL EQUIPO LOCAL";channel.basicPublish("exchange_deportes", "", null, mensaje.getBytes());channel.exchangeDeclare("exchange_deportes", "fanout");
// Creamos una cola aleatoria, exclusiva y temporal (se borra al desconectar)String nombreCola = channel.queueDeclare().getQueue();
// BINDING: "Conecta mi cola temporal al exchange de deportes"channel.queueBind(nombreCola, "exchange_deportes", "");
// Consumimoschannel.basicConsume(nombreCola, true, deliverCallback, consumerTag -> {});- Direct:
// 1. Tipo DIRECTchannel.exchangeDeclare("exchange_logs", "direct");
// 2. Enviamos un error graveString mensaje = "Fallo crítico en base de datos";String severidad = "error"; // Esta es la Routing Keychannel.basicPublish("exchange_logs", severidad, null, mensaje.getBytes());channel.exchangeDeclare("exchange_logs", "direct");String nombreCola = channel.queueDeclare().getQueue();
// BINDING: "Solo envíame mensajes si la routing key es EXACTAMENTE 'error'"channel.queueBind(nombreCola, "exchange_logs", "error");
channel.basicConsume(nombreCola, true, deliverCallback, consumerTag -> {});- Topic:
channel.exchangeDeclare("exchange_noticias", "topic");
String mensaje = "El Madrid gana la liga";// Clave: Categoría.Subcategoría.Equipochannel.basicPublish("exchange_noticias", "deportes.futbol.madrid", null, mensaje.getBytes());// BINDING: El asterisco (*) sustituye a UNA palabra (el equipo)// Recibirá: deportes.futbol.madrid, deportes.futbol.barcachannel.queueBind(nombreCola, "exchange_noticias", "deportes.futbol.*");// BINDING: La almohadilla (#) sustituye a CUALQUIER cantidad de palabras// Recibirá: deportes.futbol.madrid, deportes.tenis, deportes.waterpolo.femeninochannel.queueBind(nombreCola, "exchange_noticias", "deportes.#");- Header:
channel.exchangeDeclare("exchange_archivos", "headers");
Map<String, Object> cabeceras = new HashMap<>();cabeceras.put("formato", "pdf");cabeceras.put("tipo", "informe");
AMQP.BasicProperties props = new AMQP.BasicProperties.Builder() .headers(cabeceras) .build();
channel.basicPublish("exchange_archivos", "", props, mensaje.getBytes());Map<String, Object> bindingArgs = new HashMap<>();bindingArgs.put("x-match", "all"); // Deben coincidir TODAS las reglasbindingArgs.put("formato", "pdf");
channel.queueBind(nombreCola, "exchange_archivos", "", bindingArgs);Un agente es un sistema informático situado en un entorno, capaz de realizar acciones de forma autónoma y flexible para cumplir los objetivo de su dueño. Un agente es:
- Autónomo: opera sin intervención directa, tiene control sobre su estado interno y sus acciones.
- Reactividad: percibe su entorno y responde a cambios rápidamente
- Proactividad: no solo reacciona, toma la iniciativa para cumplir objetivos a largo plazo
- Habilidad Social: interactúa con otros agentes o humanos (coopera, negocia o compite).
- Movilidad: el agente tiene la capacidad de viajar de nodo en nodo de la red preservando su estado.
La principal diferencia entre los sistemas multiagente y las redes P2P es la homogeneidad, el nivel de autonomía e inteligencia. En una red P2P los nodos que intervienen son todos homogéneos, su comportamiento es rígido y reactivo, todos los nodos realizan las mismas funciones y colaboran entre sí. Por el otro lado, los agentes son heterogéneos, cada uno se especializa en realizar una tarea o función y puede competir o colaborar con otros agentes. Además su comportamiento es proactivo y autónomo, no solo reactivo.
Los agentes se comunican siguiendo los estándares FIPA-ACL. Un mensaje FIPA tiene una estructura tipo carta que incluye:
- Performative: El tipo de acto (request, inform, agree)
- Sender/Receiver: quién envía y quién recibe
- Content: el contenido real de la comunicación
- Language & Ontology: que idioma y diccionario se usa para entender el contenido
- Protocol: a qué conversación pertenece esto
Si recibes un mensaje que no entiendes, debes responder con not-understood, si usas un acto comunicativo debes cumplir su definición oficial y no estas obligado a implementar todos los protocolos, solo el subconjunto que necesites.
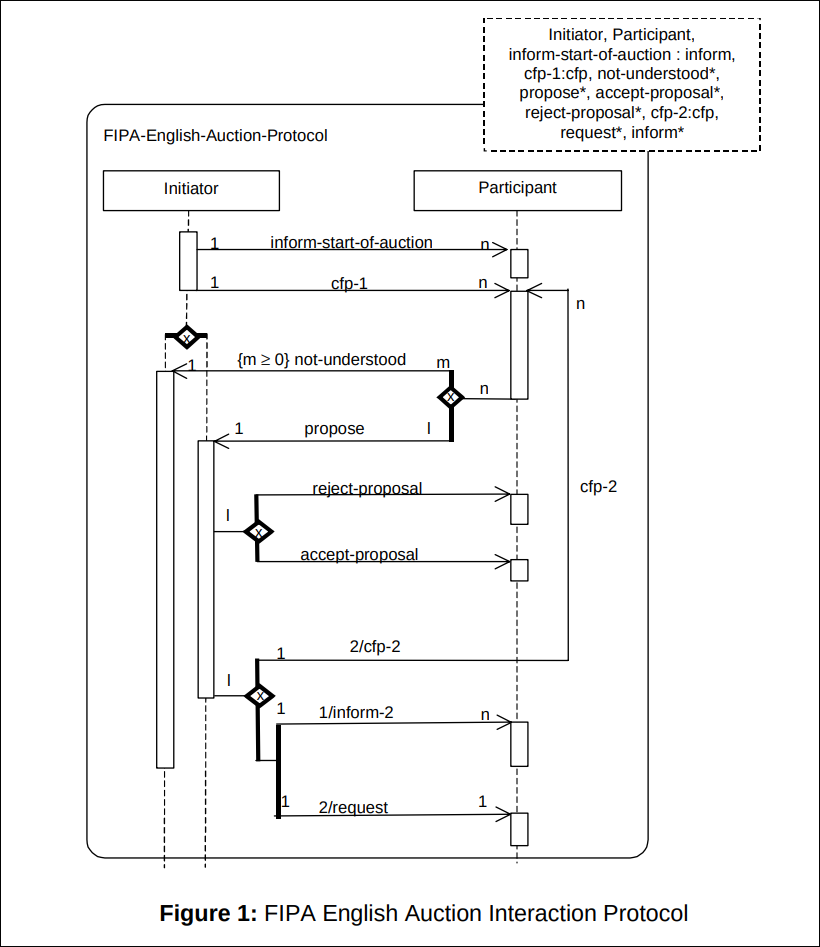
Jade es un framework de código abierto que facilita la creación de sistemas distribuidos multiagente, está escrito en Java y cumple con la FIPA. Tenemos los siguientes agentes disponibles para desarrollar el sistema:
- RMA: es la consola principal, controla la plataforma, mata y crea a otros agentes.
- DF: son las páginas amarillas del sistema, permite que los agentes se encuentren por lo que hacen y no por su nombre.
- Sniffer Agent: muestra un diagrama visual de quién envía mensajes a quién
- Instrospector Agent: permite ver el estado interno de un agente, qué comportamientos está ejecutando, la cola de mensajes pendientes y el valor de sus variables
- Log Manager Agent: gestiona los logs de la plataforma en tiempo de ejecución. Permite cambiar qué nivel de detalle se guarda sin tener que reiniciar el programa.
- Dummy Agent: un agente manual para enviar mensajes de prueba y comprobar si tu sistema responde correctamente.
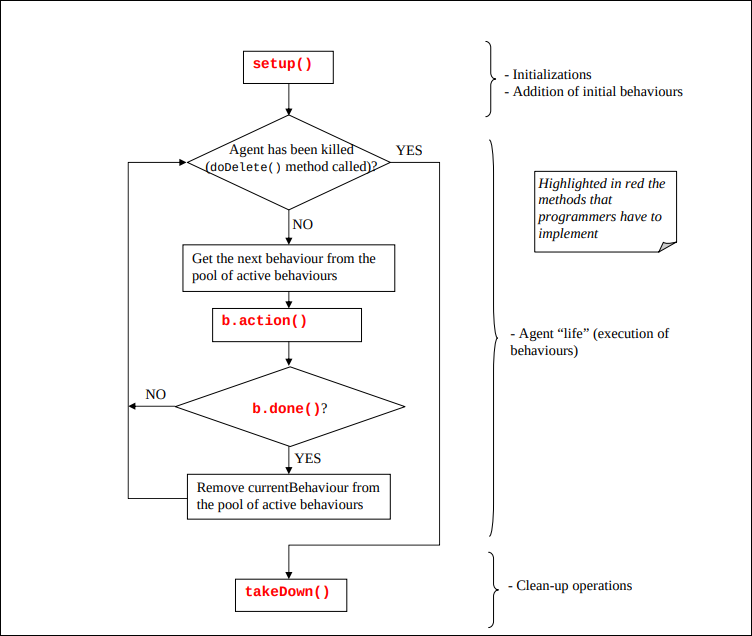
El ciclo de vida de un agente es el siguiente:
- Nacimiento (
setup): se ejecuta una sola vez al arrancar. Aquí inicializas variables y, lo más importante, añades los primeros comportamientos (addBehaviorur) a la “piscina” de tareas. - El Bucle Principal (El corazón del Agente): el agente entra en un bucle
whileque dura toda su vida. ¿El agente ha muerto (doDeltellamado)? Si ha muerto sale del bucle y va atakeDown(), si no continúa. - Ejecución de Comportamientos: el agente coge el siguiente comportamiento activo de su lista, ejecuta el método
b.action()de ese comportamiento (solo se ejecuta un paso, no todo el proceso si es largo). - Verificación: Pregunta
b.done()?. Si devuelve True el comportamiento ha terminado y se elimina de la lista, si devuelve False el comportamiento sigue vivo y se queda en la lista para la siguiente vuelta - Muerte (
takeDown()): se ejecuta antes de desaparecer. Aquí cierra conexiones a bases de datos, te desregistras de las páginas amarillas, etc.
import jade.core.Agent;
public class MiAgente extends Agent {
// 1. SETUP: Equivale al "main". Se ejecuta al nacer. protected void setup() { System.out.println("Hola, soy el agente " + getAID().getName()); // Aquí se añaden los comportamientos (el cerebro) addBehaviour(new MiComportamiento()); }
// 2. TAKEDOWN: Se ejecuta justo antes de morir (limpieza). protected void takeDown() { System.out.println("Adios mundo cruel."); }}Un agente JADE funciona en un SOLO HILO de Java. ¿Cómo puede hacer varias cosas a la vez (escuchar mensajes y calcular datos)? Usando comportamientos colaborativos, no apropiativos. Para realizar esto, el programador debe definir cuando el comportamiento debe ceder CPU de forma voluntaria a otros comportamientos (normalmente cuando se usan operaciones bloqueantes, esto se explica más abajo).
1. myBehaviour.block() (Enfoque Colaborativo)
- Mecanismo: Es un bloqueo lógico. Marca el comportamiento como “en espera” y devuelve el control al planificador del agente.
- El Hilo (Thread): No se detiene. El agente aprovecha para ejecutar otros comportamientos concurrentes.
- Despertador: El comportamiento se reactiva automáticamente cuando llega un nuevo mensaje a la cola del agente.
- Uso: Es la forma correcta de esperar mensajes dentro del método
action().
2. myAgent.blockingReceive() (Enfoque Bloqueante)
- Mecanismo: Es una llamada síncrona.
- El Hilo (Thread): Se bloquea físicamente. Detiene por completo el flujo de ejecución del hilo Java del agente.
- Consecuencia: El agente se “congela” totalmente. Ningún otro comportamiento puede ejecutarse hasta que llegue el mensaje esperado.
- Uso: Evitar en comportamientos cíclicos. Útil solo en la inicialización (
setup()) o fases lineales estrictas.
| Tipo | Clase Java | Descripción | done() devuelve… | Ejemplo |
|---|---|---|---|---|
| OneShot | OneShotBehaviour | Se ejecuta una sola vez y termina. | true | Enviar un email de bienvenida. |
| Cíclico | CyclicBehaviour | Nunca termina. Se repite infinitamente. | false | Escuchar mensajes entrantes. |
| Waker | WakerBehaviour | Se ejecuta una vez tras un tiempo de espera (Temporizador). | true | ”Despiértame en 10 segundos”. |
| Ticker | TickerBehaviour | Se ejecuta repetidamente cada X tiempo (Metrónomo). | false | Comprobar el precio de una acción cada minuto. |
| Complejo | FSMBehaviour, etc. | Máquinas de estados. Cambia de tarea según lo que pase. | Depende | Lógica compleja de negocio. |
//enviar un mensaje aclACLMessage msg = new ACLMessage(ACLMessage.INFORM); // 1. Performativemsg.addReceiver(new AID("AgenteB", AID.ISLOCALNAME)); // 2. Receptormsg.setLanguage("Castellano");msg.setContent("Está lloviendo"); // 3. Contenidosend(msg); // 4. Enviar//recibir un mensaje aclACLMessage msg = receive(); // Mira si hay mensajeif (msg != null) { // Procesar mensaje} else { block(); // ¡IMPORTANTE!}Una ontología es un contrato semántico. Es una especificación explícita de una conceptualización. Define el vocabulario (tipos, propiedades y relaciones) de un dominio específico sin ambigüedad.
El ContentManager es el componente del agente encargado de la traducción semántica entre los objetos Java (lógica interna) y el contenido textual de los mensajes (transmisión por red).
Funciona apoyándose en dos elementos que debes registrar: un Lenguaje (la sintaxis, ej. FIPA-SL) y una Ontología (el vocabulario). Su utilidad se resume en dos métodos:
fillContent(): Convierte tus objetos Java a texto para enviar un mensaje.extractContent(): Convierte el texto del mensaje recibido de nuevo a objetos Java.
Escribir ontologías a mano es tedioso y propenso a errores.
-
Protégé: Software de la Universidad de Stanford para dibujar ontologías gráficamente (clases, relaciones).
-
OntologyBeanGenerator (OBG): Un plugin para Protégé que genera el código Java automáticamente. Crea tanto la clase
Ontology(esquemas) como los Beans con sus getters y setters, listos para usar en JADE .
Tema 10
Sección titulada «Tema 10»Jess es un motor de reglas ligero y rápido escrito en Java. Permite construir software que razona usando conocimiento suministrado en forma de reglas declarativas, en lugar de código imperativo.
Un agente JADE es, por principio, monohilo (single-threaded). Esto simplifica la gestión del estado pero impone restricciones de bloqueo. Para embeber Jess, instanciamos la clase jess.Rete. El método estándar de ejecución es Rete.run(). El método Rete.run() ejecuta reglas consecutivamente y bloquea el hilo de llamada hasta que no quedan más reglas por disparar. Para evitar el bloqueo total, utilizamos una variante del método run que acepta un límite de ciclos: jess.run(int maxCycles). Esto permite que el agente razone “un poco”, atienda otras tareas (como leer mensajes), y vuelva a razonar