Capa de Transporte
Escrito por Adrián Quiroga Linares.
3.1 Introducción
Sección titulada «3.1 Introducción»La capa de transporte es un componente clave en la arquitectura de redes, cuya función es asegurar que los datos enviados desde una aplicación en el origen lleguen de manera correcta al proceso de destino.
[!Recordatorio]
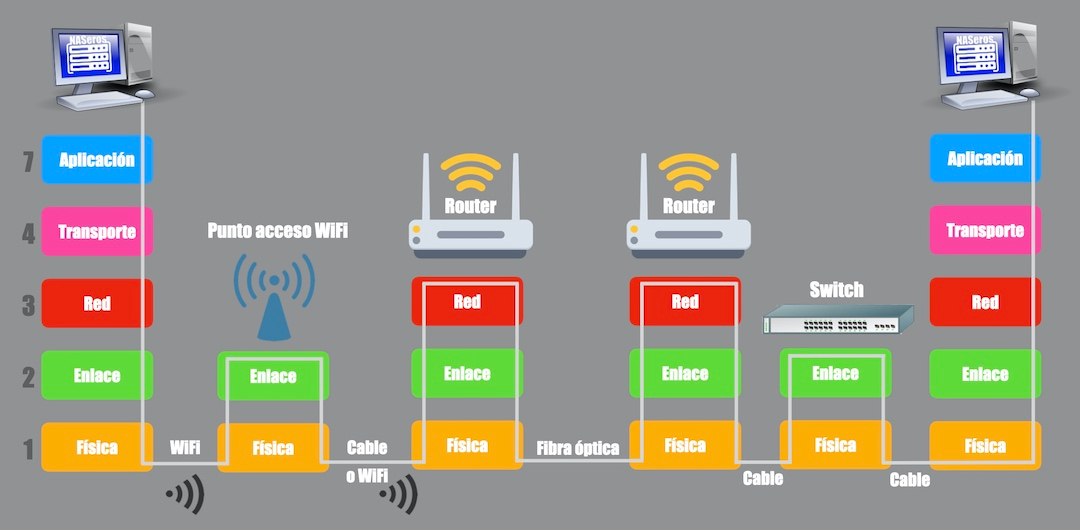
La capa de transporte se encarga de preparar los datos para la transmisión, recibe los datos que le pasa la capa de aplicación y los prepara para su transmisión dependiendo de si se utiliza TCP o UDP. Debe decidir si fragmenta los datos en segmentos (TCP) o simplemente les añade una cabecera (UDP). Una vez los datos llegan al destino se debe encargar de reconstruir los mensaje que fueran segmentados y entregarlos al proceso correcto en el sistema receptor.
La capa de transporte no necesita conocer cómo funciona el canal de transmisión, ya que asume que puede haber muchos errores en la transmisión. El objetivo es realizar una comunicación lógica entre el origen y el destino, sin importar cómo se manejen los errores en las capas inferiores
La capa de transporte está presente solo en los dispositivos de origen y destino, no en los routers intermedios. Los routers se ocupan de las capas inferiores, como la red, pero no gestionan los detalles del transporte de datos.
TCP (Transmission Control Protocol): TCP divide los mensajes en segmentos más pequeños. A cada segmento le añade una cabecera de control para asegurar la correcta transmisión y el control de errores.

UDP (User Datagram Protocol): UDP no realiza segmentación de mensajes ni garantiza la entrega ordenada. Simplemente añade una cabecera a los datos y los envía. Es más rápido, pero menos fiable que TCP.
3.2 Multiplexión y demultiplexión
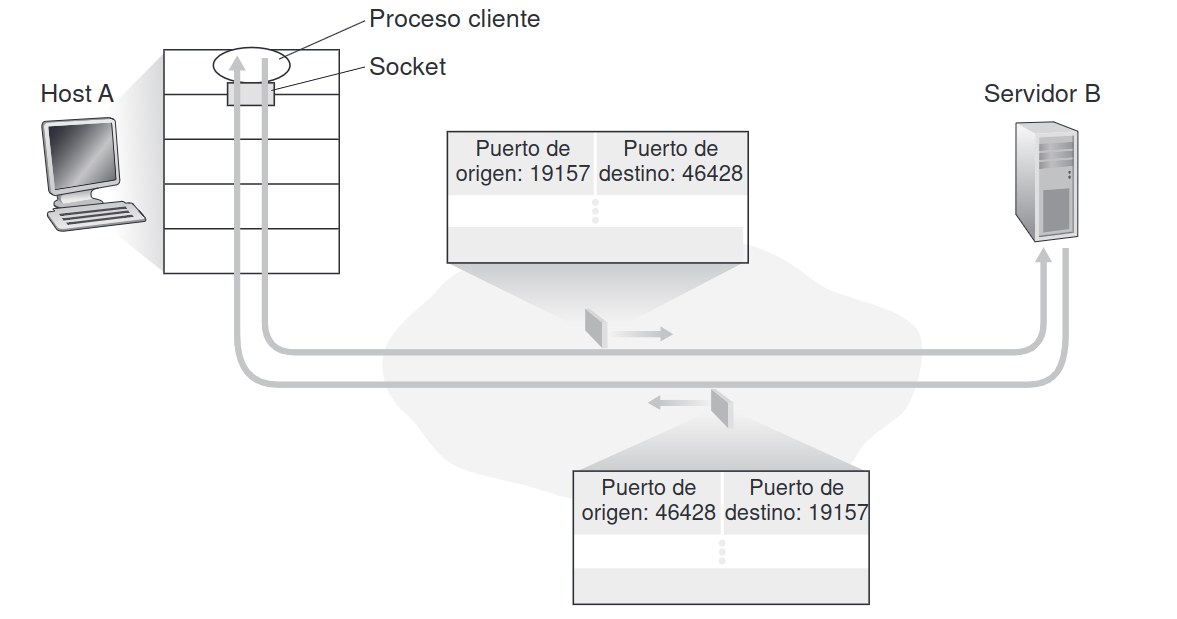
Sección titulada «3.2 Multiplexión y demultiplexión»Los mensajes pasan de la capa de aplicación a la capa de transporte a través de un socket. Los procesos escriben y leen del socket. La capa de transporte recoge los mensajes del socket y los traslada al socket destino.
3.2.1 Multiplexión
Sección titulada «3.2.1 Multiplexión»La multiplexión es el proceso en el cual la capa de transporte recoge datos de múltiples procesos de aplicación, los organiza y los envía a la capa de red. Esto se hace recorriendo cada uno de los sockets asociados a las aplicaciones, procesando los datos de cada socket, y enviando los segmentos (paquetes) correspondientes a la red. Cada proceso de aplicación tiene su propio socket, lo cual permite que varios procesos diferentes transmitan datos simultáneamente. La multiplexión asegura que los datos de distintos procesos sean recogidos y enviados a través de la red de manera ordenada.
3.2.2 Demultiplexión
Sección titulada «3.2.2 Demultiplexión»La demultiplexión ocurre en el lado del receptor. Aquí, la capa de transporte recibe segmentos de la capa de red, reconstruye los mensajes originales y los distribuye a los sockets correspondientes en función de los números de puerto que identifican a cada socket. De esta manera, los procesos en el lado del receptor pueden recoger los mensajes que les corresponden.
3.2.3 Identificación mediante puertos
Sección titulada «3.2.3 Identificación mediante puertos»Para identificar a qué socket corresponde un mensaje, se usan los números de puerto, que son enteros de 16 bits (0-65535). Estos números permiten diferenciar qué proceso debe recibir los datos en el sistema.
Los puertos entre 0-1023 están reservados para servicios bien conocidos (como HTTP o FTP), se conocen como Puertos Conocidos. Los puertos entre 1024-49152 están disponibles para las aplicaciones de usuario, se llaman Puertos Registrados.
Y los puertos restantes son los Puertos Efímeros que son los que se usan cuando por ejemplo abrimos varias pestañas de firefox simultáneamente, como no podemos usar el mismo puerto, el SO asigna a cada ventana un puerto efímero diferente, y al cerrarlas se liberan.

3.2.4 Multiplexión y Demultiplexión con sockets sin conexión (UDP)
Sección titulada «3.2.4 Multiplexión y Demultiplexión con sockets sin conexión (UDP)»En el caso de UDP (User Datagram Protocol), los sockets se identifican únicamente por la dirección IP de destino y el puerto de destino. Por ejemplo, un servidor que proporciona la hora del día a múltiples clientes (como el servicio daytime en el puerto 13) recibe datagramas de diferentes clientes y responde a cada uno de forma individual. Todos los datagramas se entregan al mismo puerto de destino, pero el puerto de origen permite que el servidor sepa a quién responder.
Si dos segmentos UDP tienen diferentes direcciones IP y/o números de puerto de origen, pero la misma dirección IP de destino y el mismo número puerto de destino, entonces los dos segmentos se enviarán al mismo proceso de destino a través del mismo socket de destino
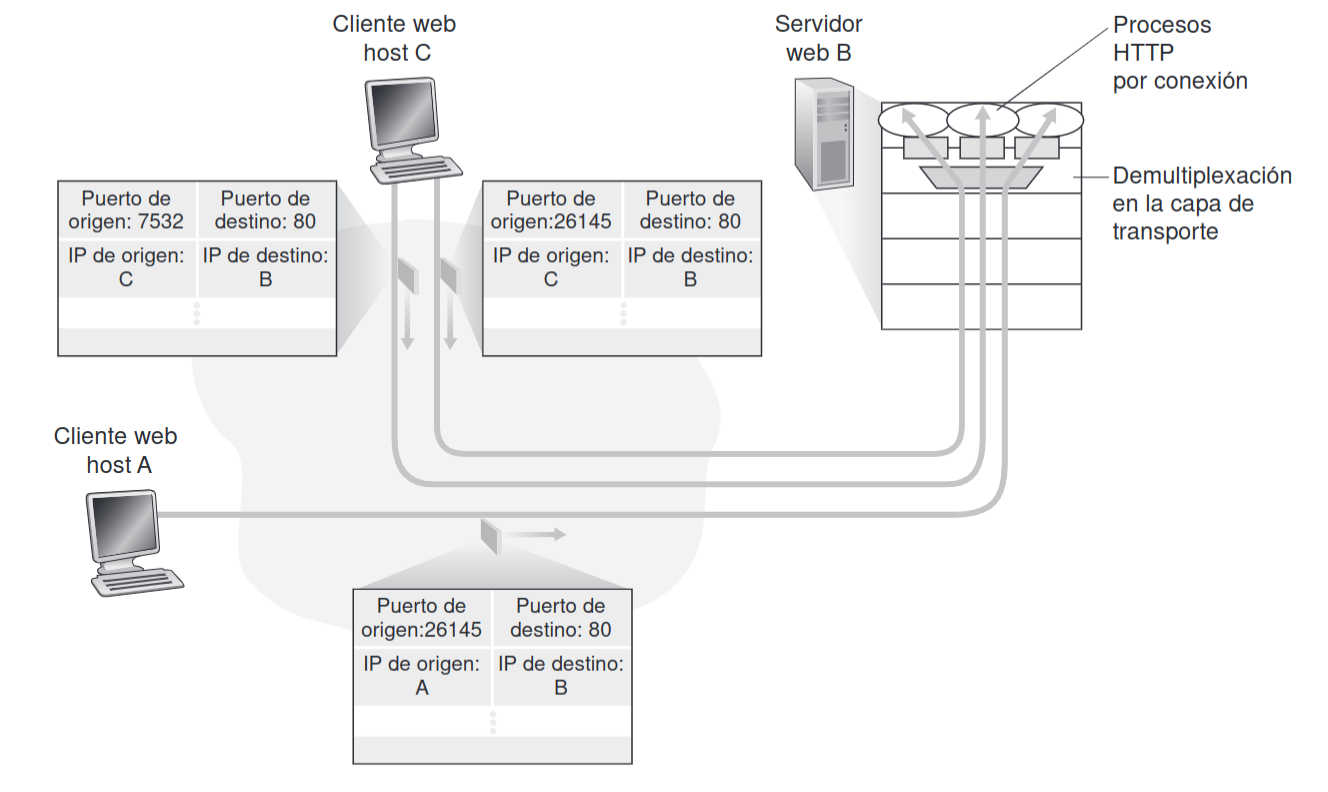
3.2.5 Multiplexión y Demultiplexión con sockets orientados a conexión (TCP)
Sección titulada «3.2.5 Multiplexión y Demultiplexión con sockets orientados a conexión (TCP)»En el caso de TCP (Transmission Control Protocol), los sockets se identifican con una tupla de 4 elementos: la dirección IP de origen, la dirección IP de destino, el puerto de origen y el puerto de destino. Por tanto, cuando un segmento TCP llega a un host procedente de la red, el host emplea los cuatro valores para dirigir (demultiplexar) el segmento al socket apropiado.
En particular, y al contrario de lo que ocurre con UDP, dos segmentos TCP entrantes con direcciones IP de origen o números de puerto de origen diferentes (con la excepción de un segmento TCP que transporte la solicitud original de establecimiento de conexión) serán dirigidos a dos sockets distintos. Cada conexión es atendida por un proceso o hilo.
En TCP, hay dos tipos de sockets:
- Socket de servidor: Solo espera conexiones de clientes.
- Socket de conexión: Se encarga de manejar una conexión específica.
Cuando un cliente establece una conexión con un servidor, el socket de servidor transfiere la conexión a un socket de conexión dedicado a esa interacción. Así, múltiples conexiones pueden ser manejadas simultáneamente por un solo servidor, como ocurre en servicios como telnet o HTTP.
Estos mecanismos permiten que múltiples aplicaciones en diferentes dispositivos puedan comunicarse de manera eficiente y ordenada a través de la red, utilizando un solo enlace físico pero gestionando múltiples flujos de datos simultáneos.
3.3 Capa de Transporte Sin Conexión: UDP
Sección titulada «3.3 Capa de Transporte Sin Conexión: UDP»UDP (User Datagram Protocol) es un protocolo de transporte de capa 4 en el modelo OSI. A diferencia de TCP, es un protocolo sin conexión, lo que significa que no establece una conexión entre el emisor y el receptor antes de enviar los datos, ni garantiza que los datos lleguen en orden o sin errores. Es simple y poco sofisticado.
En el emisor, UDP coge el mensaje que se va a enviar y le añade una cabecera simple para formar un segmento. La cabecera UDP solo tiene cuatro campos (puerto origen, puerto destino, longitud total y suma de comprobación). La longitud total incluye el tamaño del segmento entero, contado la cabecera y datos. La suma de comprobación es un mecanismo para detectar errores en los datos. (no se incluyen las IPs pero ya se verá mas adelante.)
La suma de comprobación se usa para detectar errores en el segmento (tanto en los datos como en la cabecera). En el origen, se suman todas las palabras de 16 bits del segmento. Luego se realiza un complemento a 1 del resultado y se inserta en el campo de suma de comprobación. Al llegar al destino, se recalcula la suma de comprobación y si coincide con la original, significa que el paquete llegó sin errores.

En el receptor, UDP verifica si el segmento llegó sin errores utilizando la suma de comprobación. Si no hay errores, los datos se pasan al socket para ser procesados por la aplicación.
Es un servicio sin conexión puesto que no hay una negociación previa entre emisor y receptor. Los segmentos simplemente se envían sin establecer una conexión. Esto reduce la latencia ya que se evita el famoso handshake de TCP que se explicará más adelante. Sin embargo, UDP no garantiza la entrega de segmentos ni los retransmite si se pierden o llegan con errores.
Tiene un procesamiento rápido y bajo consumo de recursos, debido a que no mantiene el estado de la conexión ni tiene mecanismos de control de errores sofisticados, UDP es muy eficiente. Esto lo hace ideal para servidores que necesitan atender a muchos clientes simultáneamente o para aplicaciones que priorizan la velocidad.
La cabecera de UDP es mucho más pequeña que la de TCP, lo que implica un procesamiento más rápido y menos sobrecarga de almacenamiento y transmisión. Las aplicaciones que usan UDP pueden implementar sus propios mecanismos de control si es necesario, como la numeración de datos o la detección de errores adicional.
Ejemplos de usos de UDP:
- Traducción de nombres (DNS)
- Protocolos de encaminamiento (RIP)
- Administración de red (SNMP)
- Servidor de archivos remoto (NFS)
3.4 Fundamentos de la transmisión fiable
Sección titulada «3.4 Fundamentos de la transmisión fiable»La transmisión fiable se refiere a la capacidad de garantizar que los datos enviados a través de una red lleguen correctamente al receptor. Para lograrlo, se utilizan protocolos de retransmisión conocidos como ARQ (Automatic Repeat reQuest). Estos protocolos retransmiten paquetes si se detecta un error o si un paquete no llega al destino.
Las confirmaciones de recepción son los ACKs (ACKnowledgment number)
3.2.1 Protocolo ARQ: Parar y esperar
Sección titulada «3.2.1 Protocolo ARQ: Parar y esperar»En este protocolo, el emisor envía un paquete y luego se detiene a esperar una confirmación (ACK) del receptor antes de enviar el siguiente paquete. Es un proceso simple pero ineficiente si hay mucha latencia o pérdida de paquetes.
Si no se producen errores, el receptor recibe el paquete correctamente y envía un ACK (confirmación) al emisor. El número del ACK es el número del siguiente paquete esperado. Una vez que el emisor recibe el ACK, envía el siguiente paquete.
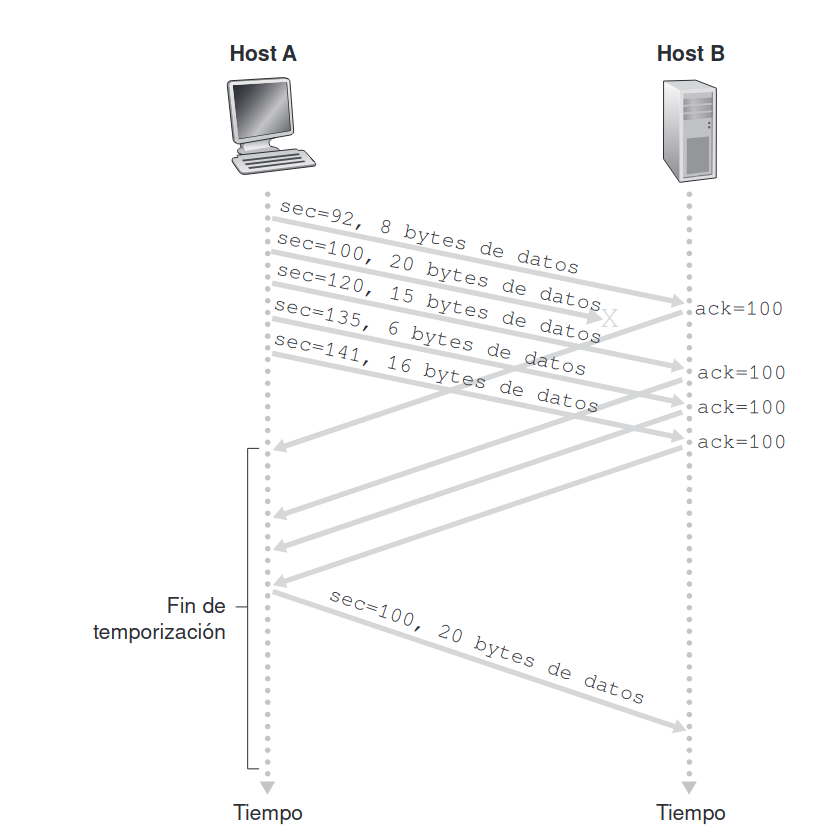
Si se pierden paquetes, si un paquete se pierde en el camino o llega con errores, el receptor no enviará el ACK. El emisor tiene un temporizador que empieza a contar cuando se envía el paquete. Si no recibe el ACK antes de que el temporizador expire, retransmite el paquete.
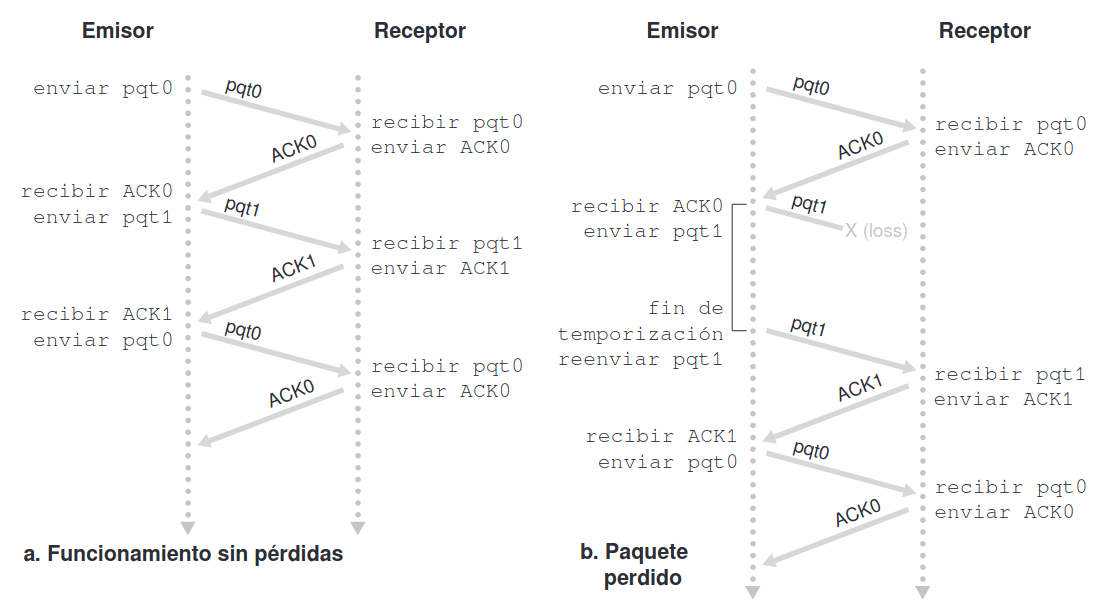 Si se pierde el ACK, el emisor no sabrá que el receptor recibió el paquete. Entonces, cuando el temporizador expire, retransmitirá el paquete. El receptor, al recibir un paquete duplicado (porque ya lo procesó antes), simplemente reconoce que es un duplicado , lo descarta y envía el ACK correspondiente nuevamente.
Si se pierde el ACK, el emisor no sabrá que el receptor recibió el paquete. Entonces, cuando el temporizador expire, retransmitirá el paquete. El receptor, al recibir un paquete duplicado (porque ya lo procesó antes), simplemente reconoce que es un duplicado , lo descarta y envía el ACK correspondiente nuevamente.
Si el temporizador se configura con un tiempo muy corto o hay congestión en la red, tanto los paquetes como los ACK pueden retrasarse. El emisor puede recibir duplicados de ACKs o de paquetes debido a este retraso, pero los identifica por el número de secuencia y los ignora si ya fueron procesados.
Un NAK (Negative-Acknowledge Character) implica que si se recibe, el protocolo retransmite el último paquete y espera a recibir un mensaje ACK o NAK del receptor en respuesta al paquete de datos retransmitido.
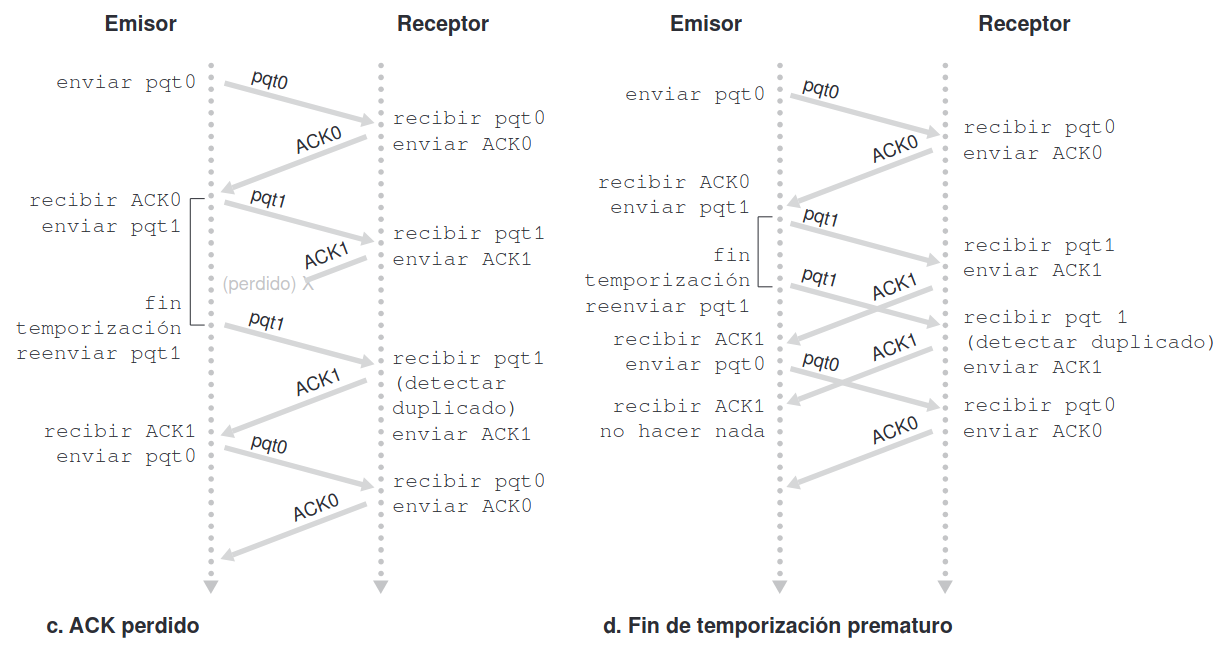
Si el emisor recibe un ACK o NAK alterados reenvía el paquete. Sin embargo este método introduce paquetes duplicados en el canal emisor-receptor. La principal dificultad con los paquetes duplicados es que el receptor no sabe si el último paquete ACK o NAK recibido correctamente en el emisor. Por tanto no puede saber si un paquete entrante contiene datos nuevos o se trata de una retransmisión. Para solucionar esto surgen los números de secuencia.
Cuando recibe un paquete fuera de secuencia, el receptor envía un paquete ACK para el paquete que ha recibido. Cuando recibe un paquete corrompido, el receptor envía una respuesta de reconocimiento negativo. Podemos conseguir el mismo efecto que con una respuesta NAK si, en lugar de enviar una NAK, enviamos una respuesta de reconocimiento positivo (ACK) para el último paquete recibido correctamente. Un emisor que recibe dos respuestas ACK para el mismo paquete (es decir, recibe respuestas ACK duplicadas) sabe que el receptor no ha recibido correctamente el paquete que sigue al que está siendo reconocido (respuesta ACK) dos veces.
Sin embargo si vence el temporizador, se van a enviar paquetes duplicados todo el tiempo. Por ello debemos hacer que en vez de dos, tres ACKs equivalen a un NAK.
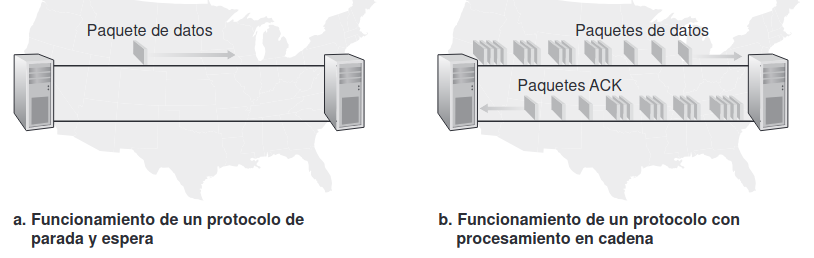
Inconveniente de parar y esperar
Sección titulada «Inconveniente de parar y esperar»La poca utilización de enlace:
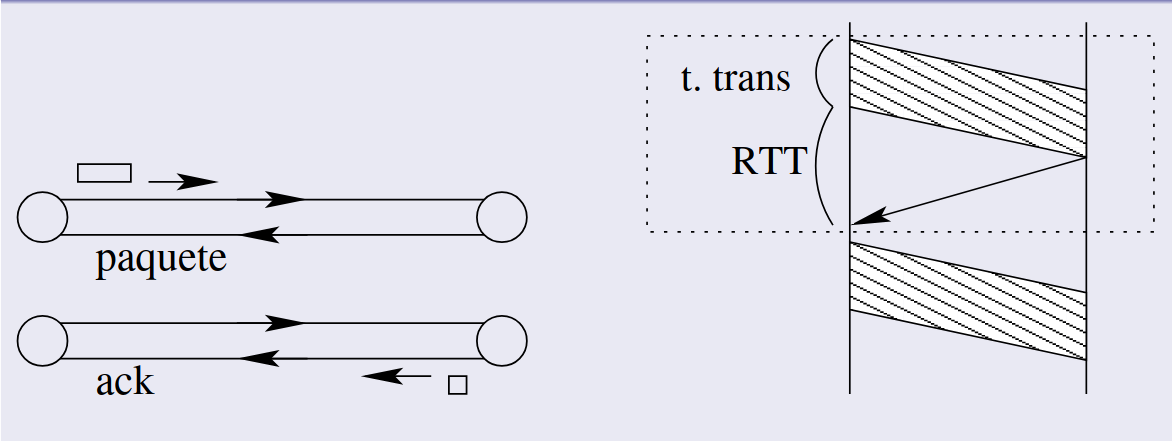
La utilización del enlace es la proporción del tiempo en que el emisor realmente está enviando datos, frente al tiempo total (que incluye tanto la transmisión como la espera). Es decir, es el tiempo útil dividido por el tiempo total. Se calcula de la siguiente forma:
3.2.2 ARQ con ventana deslizante (entubamiento)
Sección titulada «3.2.2 ARQ con ventana deslizante (entubamiento)»El protocolo ARQ con ventana deslizante, también conocido como entubamiento, es una mejora sobre el protocolo “parar y esperar”, y su principal ventaja es que reduce el tiempo perdido esperando confirmaciones (ACKs). En lugar de enviar un paquete y esperar una confirmación antes de enviar el siguiente, el emisor puede enviar varios paquetes consecutivos (hasta un número máximo antes de recibir los ACKs). Esto mejora considerablemente la utilización del enlace.
La utilización del enlace se mejora al permitir que se transmitan múltiples paquetes antes de recibir un ACK.
U = \frac{N \cdot t_{\text{trans}}}{RTT + t_{\text{trans}}}$$ La utilización es **máxima** cuando:N \geq 1 + \frac{RTT}{t_{\text{trans}}}
undefined\text{ventana de congestión} = \text{Ttrans} \times \text{RTT}
\text{Ttrans} = \frac{\text{ventana de congestión}}{\text{RTT}}
undefined\text{Ttrans} = \frac{500 \times 8}{0.2} = 20 , \text{kbps}.
undefined